AI vs. Traditional Strain Optimization: A New Era of Validation, Efficiency, and Biological Relevance
This article provides a comprehensive analysis for researchers and drug development professionals on the paradigm shift from traditional, empirical strain optimization methods to AI-driven, predictive approaches.
AI vs. Traditional Strain Optimization: A New Era of Validation, Efficiency, and Biological Relevance
Abstract
This article provides a comprehensive analysis for researchers and drug development professionals on the paradigm shift from traditional, empirical strain optimization methods to AI-driven, predictive approaches. We explore the foundational principles of both methodologies, detailing how AI leverages big data and machine learning for target identification and virtual screening. The piece offers a practical guide to implementing AI workflows, from generative molecular design to automated high-throughput validation. It critically examines key challenges, including data quality, model interpretability, and ethical considerations, while presenting a robust framework for the comparative validation of AI-generated strains against traditional benchmarks. Finally, the discussion synthesizes the transformative potential of AI, outlining a future where human expertise is augmented by computational power to accelerate therapeutic discovery, supported by emerging regulatory frameworks and a focus on human-relevant models.
From Pipettes to Predictions: The Foundational Shift in Strain Optimization
This guide compares the performance of traditional empirical methods against Artificial Intelligence (AI)-driven approaches in strain optimization and method validation for drug development. For researchers and scientists, this objective comparison is critical for making informed decisions in research and development (R&D) strategy.
Quantifying the Traditional vs. AI-Driven Paradigm
The following table summarizes the core performance differences between the traditional empirical paradigm and the modern AI-driven approach across key R&D metrics.
| Performance Metric | Traditional Empirical Methods | AI-Driven Methods | Supporting Data / Examples |
|---|---|---|---|
| Development Timeline | 12–15 years from discovery to market [1]. | Dramatically accelerated; AI can rapidly prioritize candidates from thousands of possibilities [2]. | COVID-19 vaccines demonstrated compressed timelines through accelerated, data-driven trials [2]. |
| Attrition Rate | Over 90% of candidates fail between preclinical and licensure [2]. | Reduced attrition via improved predictive accuracy early in discovery [2]. | AI epitope prediction achieves ~87.8% accuracy, outperforming traditional tools by ~59%, reducing failed experiments [2]. |
| R&D Cost | $1–2.6 billion per novel drug [1]. | Significant cost reduction by minimizing physical screening and failed experiments [2]. | Collaborative method validation models demonstrate substantial cost savings by reducing redundant work [3]. |
| Method Validation & Transfer | Time-consuming, laborious, and often performed independently by each laboratory, leading to resource redundancy [3]. | Streamlined via collaborative models and published data; subsequent labs can perform verifications instead of full validations [3]. | A collaborative validation model allows Forensic Science Service Providers (FSSPs) to adopt published, peer-reviewed methods, drastically cutting activation energy for implementation [3]. |
| Experimental Design | Relies on human intuition and iterative, time-consuming trial-and-error processes [4]. | AI models complex parameter-outcome relationships, proposing efficient strategies and enabling "self-driven laboratories" [4]. | AI techniques like Bayesian optimization automate experimental design, saving time and materials by avoiding unnecessary trials [4]. |
| Predictive Capability | Limited accuracy; for example, traditional T-cell epitope predictors showed poor correlation with experimental validation [2]. | High predictive power; modern deep learning models match or exceed the accuracy of specific laboratory assays [2]. | In one study, an AI model (MUNIS) for T-cell epitope prediction showed 26% higher performance than the best prior algorithm [2]. |
Experimental Protocols and Workflows
Protocol for Traditional, Empirical Drug Discovery
This multi-stage, sequential process is characterized by high manual effort and long cycle times.
- Target Identification & Validation: Initiated based on literature and preliminary data. Involves extensive in vitro and in vivo investigations to prosecute a desired target, a process described as multifunctional [1].
- Hit Discovery: Uses High-Throughput Screening (HTS) of large compound libraries against the target. This is a resource-intensive, trial-and-error-based experimental screening process [1].
- Lead Optimization: Medicinal chemists synthesize structural analogues of "hit" compounds. Each analogue is tested iteratively in in vitro and in vivo models to maximize biological activity and minimize toxicity [1].
- Preclinical & Clinical Development: The selected drug candidate undergoes rigorous toxicity evaluation in animal models. If successful, it progresses through Phases I-III of clinical trials in humans, a process lasting many years [1].
Protocol for AI-Driven Strain Optimization & Validation
This workflow is iterative and data-centric, leveraging AI to guide and accelerate experimental phases.
- AI-Assisted Target Identification: Data mining of biomedical databases (genomics, proteomics, publications) identifies and prioritizes potential disease targets [1]. AI can flag less obvious, high-value targets [2].
- In Silico Screening & Design: AI models, including Generative AI and Graph Neural Networks (GNNs), are used to screen virtual compound libraries or generate novel candidate molecules (e.g., anti-tumor agents, optimized antigens) with desired properties [1] [2].
- AI-Driven Experimental Design & Validation: AI, particularly Bayesian Optimization, designs optimal experiment sequences to validate predictions with minimal lab work. This can be implemented in partially or fully autonomous self-driving laboratories (SDLs) [4]. For method validation, a collaborative model is used where an originating lab publishes a full validation, and subsequent labs perform a streamlined verification [3].
- Rapid Experimental Validation: A focused set of AI-prioritized candidates is synthesized and tested in vitro (e.g., binding assays, cell-based studies) [2]. Promising candidates proceed to in vivo validation in animal models.
The Scientist's Toolkit: Key Research Reagent Solutions
The following table details essential reagents and materials central to conducting validation and screening experiments in this field.
| Research Reagent / Material | Function in Experimental Protocols |
|---|---|
| Monoclonal Antibodies | Used as standard reagents in analytical platform technologies (APTs) for common biopharmaceuticals like monoclonal antibody products to lower validation uncertainty [5]. |
| Patient-Specific Cancer Vaccines | Represent a challenge for analytical method development, requiring tests for both non-patient-specific manufacturing consistency and patient-specific critical quality attributes [5]. |
| Quality Control (QC) Materials | Supplied by vendors with instrumentation to save time in preparing chemicals and developing quality assurance; these are crucial for method validation [3]. |
| Genotoxic Impurities | A critical component that must be monitored in a product; its profile is a key consideration during analytical method development and validation [6]. |
| Reference Standards | Qualified using a two-tiered approach per FDA guidance, comparing new working reference standards with a primary reference standard to ensure linkage to clinical trial material [5]. |
| HLA–Peptide Interaction Datasets | Large-scale datasets (e.g., >650,000 interactions) used to train deep learning models for highly accurate T-cell epitope prediction, substituting for wet-lab screens [2]. |
| NCI-14465 | NCI-14465, MF:C20H19ClN6, MW:378.9 g/mol |
| SON38 | SON38, MF:C21H25ClN4O4, MW:432.9 g/mol |
Performance Analysis of AI vs. Traditional Methods in Key Areas
Epitope Prediction for Vaccine Development
- Traditional Method Performance: Relied on motif-based or homology-based methods, which often failed to detect novel epitopes. Accuracy for B-cell epitope prediction was low, around 50–60% [2]. Experimental methods like peptide microarrays, while accurate, are slow and costly [2].
- AI-Driven Performance: Modern deep learning models, such as Convolutional Neural Networks (CNNs) and Graph Neural Networks (GNNs), have revolutionized prediction. For example, NetBCE achieved a cross-validation ROC AUC of ~0.85, substantially outperforming traditional tools [2]. The MUNIS model for T-cell epitopes showed a 26% higher performance than the best prior algorithm and successfully identified novel epitopes later validated experimentally [2].
Analytical Method Validation
- Traditional Method Challenges: Validation is a "time-consuming and laborious process" when performed independently by individual laboratories [3]. This leads to tremendous resource redundancy, with 409 US FSSPs each performing similar validations with minor differences [3].
- AI and Collaborative Model Benefits: A collaborative validation model, where one lab publishes a full validation and others perform abbreviated verifications, saves significant effort [3]. Furthermore, AI-driven analytics can transform real-time data into actionable insights for dynamic decision-making, predicting disruptions, and recommending adjustments [7].
The field of biological research is undergoing a profound transformation, moving from traditional observation-heavy methods to a new era of data-driven prediction. This revolution is powered by the convergence of artificial intelligence (AI) and the vast, complex datasets of modern biology. Where traditional strain optimization relied on iterative laboratory experiments, AI-driven approaches can now predict optimal genetic modifications by learning from massive biological datasets. This paradigm shift enables researchers to move from descriptive biology to truly predictive biology, dramatically accelerating the design of microbial strains for therapeutic development, bio-production, and fundamental biological understanding.
The core of this transformation lies in AI's ability to identify complex, non-linear patterns within high-dimensional biological data—patterns that often elude human researchers and traditional statistical methods. Machine learning algorithms, particularly deep learning models, can process multimodal data including genomic sequences, protein structures, metabolomic profiles, and phenotypic readouts to build predictive models of biological systems. This capability is fundamentally changing the throughput, cost, and strategic approach to biological engineering and drug development.
AI-Driven vs. Traditional Strain Optimization: A Comparative Analysis
Fundamental Methodological Differences
Traditional strain optimization follows a linear, hypothesis-driven approach that relies heavily on manual experimentation and researcher intuition. The process typically begins with random mutagenesis or rational design based on existing biological knowledge, followed by laborious screening and selection of improved variants. This method is inherently limited by researchers' prior knowledge and the practical constraints of laboratory throughput. Each design-build-test cycle can take weeks or months, with success heavily dependent on the initial hypothesis and the quality of the screening assay.
In contrast, AI-driven strain optimization operates as a parallel, data-driven discovery engine. AI models, particularly generative algorithms, can explore the biological design space more comprehensively by learning from existing experimental data and generating novel designs that satisfy multiple optimality criteria simultaneously. These systems can propose genetic modifications that would be non-intuitive to human designers, effectively expanding the solution space beyond conventional biological knowledge. The AI approach integrates diverse data types—from genomic sequences to high-content phenotyping—to build predictive models that simulate strain performance before physical construction, dramatically reducing the number of experimental cycles required.
Table 1: Methodological Comparison Between Traditional and AI-Driven Approaches
| Aspect | Traditional Methods | AI-Driven Approaches |
|---|---|---|
| Core Philosophy | Hypothesis-driven, knowledge-based design | Data-driven, exploratory design space exploration |
| Experimental Design | Sequential design-build-test cycles | Parallel in silico prediction with focused validation |
| Knowledge Dependency | Relies on established biological pathways and prior knowledge | Discovers novel patterns and non-intuitive designs from data |
| Data Utilization | Limited to direct, hypothesis-relevant data | Integrates multimodal data (genomic, proteomic, phenotypic) |
| Typical Workflow | Linear progression with limited iteration | Iterative learning with continuous model improvement |
| Key Limitation | Constrained by researcher intuition and screening capacity | Dependent on data quality, quantity, and computational resources |
Quantitative Performance Comparison
Recent studies and commercial implementations demonstrate the dramatic performance advantages of AI-driven approaches across multiple metrics. In clinical trial operations, AI systems have demonstrated a 42.6% reduction in patient screening time while maintaining 87.3% accuracy in matching patients to trial criteria [8]. These efficiency gains translate directly to strain optimization contexts, where AI-guided screening can identify promising candidates from vast genetic libraries with similar improvements in speed and accuracy.
The economic impact is equally significant. Major pharmaceutical companies report up to 50% reduction in process costs through AI-powered automation, with medical coding systems saving approximately 69 hours per 1,000 terms coded while achieving 96% accuracy compared to human experts [8]. In drug discovery contexts, AI platforms have compressed discovery timelines from the typical 5-6 years to as little as 18 months from target identification to Phase I trials, as demonstrated by Insilico Medicine's generative-AI-designed idiopathic pulmonary fibrosis drug [9]. Companies like Exscientia report in silico design cycles approximately 70% faster than industry norms, requiring 10x fewer synthesized compounds to identify viable candidates [9].
Table 2: Quantitative Performance Metrics: Traditional vs. AI-Driven Methods
| Performance Metric | Traditional Methods | AI-Driven Methods | Improvement Factor |
|---|---|---|---|
| Typical Discovery Timeline | 5-6 years (drug discovery) | 18-24 months | 3-4x faster |
| Design Cycle Time | Weeks to months | Days to weeks | ~70% reduction |
| Compounds Required | Hundreds to thousands | 10x fewer | 10x efficiency gain |
| Data Processing Speed | Manual review: ~69 hours/1K terms | Automated: 96% accuracy, minimal time | >10x faster |
| Screening Accuracy | Manual accuracy limits | 87.3% matching accuracy | Significant improvement |
| Error Rates | Human error in repetitive tasks | 8.48% (vs. 54.67% manual) | 6.44x improvement |
Experimental Validation: Protocols and Data
Case Study: AI-Assisted Data Cleaning in Clinical Trials
A controlled experimental study with experienced medical reviewers (n=10) directly compared traditional manual data cleaning against an AI-assisted platform (Octozi) that combines large language models with domain-specific heuristics [10]. The study employed a within-subjects design where each participant served as their own control, minimizing inter-individual variability. Participants with minimum two years of experience in medical data review and proficiency in adverse event adjudication were recruited from pharmaceutical companies, contract research organizations, and academic medical centers.
The experimental protocol utilized synthetic datasets derived from a comprehensive Phase III oncology trial database containing electronic data capture information across 51 separate case report form datasets for over 150 patients. Researchers strategically selected 8 CRFs directly relevant to adverse event assessment and documentation. To create synthetic patients while preserving complete anonymity, they employed a library-based refinement generation approach, constructing comprehensive libraries of clinical elements by extracting all unique adverse events, concomitant medications, ancillary procedures, and medical history entries from the original dataset.
The evaluation measured performance across six specific discrepancy categories: (1) inappropriate concomitant medication to treat an adverse event, (2) misaligned timing of concomitant medication administration and adverse events, (3) incorrect severity scores attached to adverse events based on description, (4) mismatched dosing changes, (5) incorrect causality assessment of adverse events, and (6) lack of supporting data for adverse events [10]. Results demonstrated that AI assistance increased data cleaning throughput by 6.03-fold while simultaneously decreasing cleaning errors from 54.67% to 8.48% (a 6.44-fold improvement). Crucially, the system reduced false positive queries by 15.48-fold, minimizing unnecessary site burden [10].
Case Study: Generative AI for Protein Binder Design
The development of BoltzGen by MIT researchers represents a groundbreaking advancement in AI-driven protein design [11]. Unlike previous models limited to either structure prediction or protein design, BoltzGen unified these capabilities while maintaining state-of-the-art performance across tasks. The model incorporates three key innovations: ability to carry out varied tasks unifying protein design and structure prediction, built-in constraints informed by wet-lab collaborators to ensure physical and chemical feasibility, and a rigorous evaluation process testing on "undruggable" disease targets.
The experimental protocol involved testing BoltzGen on 26 targets, ranging from therapeutically relevant cases to ones explicitly chosen for their dissimilarity to the training data. This comprehensive validation took place in eight wet labs across academia and industry, demonstrating the model's breadth and potential for breakthrough drug development [11]. The model demonstrated particular strength in generating novel protein binders ready to enter the drug discovery pipeline, expanding AI's reach from understanding biology toward engineering it.
Industry collaborators like Parabilis Medicines confirmed BoltzGen's transformative potential, noting that adopting BoltzGen into their existing computational platform "promises to accelerate our progress to deliver transformational drugs against major human diseases" [11]. This case exemplifies how AI-driven approaches can address previously intractable biological design challenges through more generalizable physical patterns learned from diverse examples.
Visualization of Workflows
Traditional Strain Optimization Workflow
AI-Driven Strain Optimization Workflow
The Scientist's Toolkit: Essential Research Reagents and Solutions
Successful implementation of AI-driven predictive biology requires both computational tools and specialized experimental resources. The following table details key research reagent solutions essential for conducting rigorous comparisons between AI-driven and traditional strain optimization methods.
Table 3: Essential Research Reagents and Solutions for AI-Driven Strain Optimization
| Research Reagent/Solution | Function & Application | AI-Specific Considerations |
|---|---|---|
| 3D Cell Culture Systems (MO:BOT Platform) | Automated seeding, media exchange, and quality control for organoids and complex cell models | Provides standardized, reproducible data for AI training; enables human-relevant models that improve prediction accuracy [12] |
| Automated Liquid Handlers (Tecan Veya, Eppendorf Systems) | High-precision liquid handling for reproducible assay execution | Ensures data consistency critical for AI model training; reduces human-induced variability in validation experiments [12] |
| Protein Expression Systems (Nuclera eProtein Discovery) | Rapid protein production from DNA to purified protein in <48 hours | Accelerates validation of AI-predicted protein designs; enables high-throughput testing of AI-generated candidates [12] |
| Multi-Omics Integration Platforms (Sonrai Discovery Platform) | Integration of imaging, genomic, proteomic, and clinical data into unified analytical framework | Provides structured, multimodal data essential for training sophisticated AI models; enables cross-domain pattern recognition [12] |
| Trusted Research Environments (TREs) | Secure computing environments for sensitive biological data | Enables privacy-preserving AI training on proprietary or clinical datasets; essential for regulatory compliance [13] |
| Lab Data Management Systems (Cenevo/Labguru) | Unified platforms for experimental data capture, management, and analysis | Provides clean, structured data pipelines for AI consumption; resolves data fragmentation that impedes model training [12] |
| LEI-401 | LEI-401, MF:C24H31N5O2, MW:421.5 g/mol | Chemical Reagent |
| Hsd17B13-IN-83 | Hsd17B13-IN-83, MF:C23H14Cl2F4N4O4, MW:557.3 g/mol | Chemical Reagent |
Regulatory and Implementation Considerations
The integration of AI into biological research and drug development requires careful attention to regulatory standards and practical implementation challenges. In early 2025, the FDA released comprehensive draft guidance titled "Considerations for the Use of Artificial Intelligence to Support Regulatory Decision-Making for Drug and Biological Products," establishing a risk-based assessment framework for AI validation [8]. This framework categorizes AI models into three risk levels based on their potential impact on patient safety and trial outcomes, with corresponding validation requirements.
A significant implementation challenge involves addressing bias and fairness in AI models. Studies document concerning cases where AI diagnostic tools showed reduced accuracy for specific demographic groups compared to others, often reflecting biases present in training data [8]. Organizations must implement comprehensive data audit processes that examine training datasets for demographic representation and conduct fairness testing across population subgroups. The "human-in-the-loop" approach, where researchers guide, correct, and evaluate AI algorithms, has emerged as a critical strategy for maintaining scientific oversight while leveraging AI capabilities [13].
Successful AI implementation also requires substantial change management strategies. Healthcare professionals need new skills and modified workflows to effectively use AI-powered tools in clinical practice [8]. Comprehensive training programs must address both technical aspects of AI system operation and practical integration strategies for research workflows. Organizations increasingly establish AI Centers of Excellence to coordinate implementation efforts across departments and ensure consistent validation processes.
The revolution in predictive biology represents a fundamental shift from observation-driven to prediction-driven science. AI-driven strain optimization demonstrates clear advantages over traditional methods in throughput, efficiency, and ability to discover non-intuitive biological designs. Quantitative comparisons show AI methods achieving 3-4x faster discovery timelines, 70% reductions in design cycle times, and order-of-magnitude improvements in resource utilization.
As the field advances, successful implementation will require continued attention to data quality, model transparency, and regulatory compliance. The integration of explainable AI principles, human-in-the-loop oversight, and robust validation frameworks will ensure that these powerful technologies deliver reproducible, clinically relevant advancements. Researchers who embrace this paradigm shift while maintaining scientific rigor will be positioned to drive the next generation of breakthroughs in therapeutic development and biological understanding.
The field of biologics discovery is undergoing a profound transformation, driven by the integration of advanced artificial intelligence (AI) technologies. Machine learning (ML), deep learning (DL), and generative AI are moving from theoretical promise to practical application, accelerating the development of novel therapeutic antibodies, proteins, and optimized microbial strains. This shift is particularly evident in strain optimization, where AI-driven approaches are systematically challenging and supplementing traditional methods. This guide provides an objective comparison of these core AI technologies, detailing their performance, protocols, and practical applications for researchers and drug development professionals.
The application of AI in biologics spans the entire discovery workflow, from initial target identification to lead candidate optimization. The table below compares the core technologies, their primary applications, and their performance relative to traditional methods.
Table 1: Comparison of Core AI Technologies in Biologics
| AI Technology | Primary Applications in Biologics | Key Advantages | Performance vs. Traditional Methods |
|---|---|---|---|
| Machine Learning (ML) | - Analysis of high-throughput screening data- Predictive model building for developability (e.g., stability, solubility)- Structure-Activity Relationship (SAR) modeling [14] | - Ability to learn from complex, multi-modal datasets- Identifies non-obvious patterns in data | - Reduces drug discovery costs by up to 40% [15]- Can compress discovery timelines from 5 years to 12-18 months [15] |
| Deep Learning (DL) | - Single-cell image analysis and phenotyping [16]- High-precision prediction of protein structures (e.g., AlphaFold) [15] [17]- Analysis of complex biological sequences | - Excels at processing unstructured data (images, sequences)- High accuracy in predictive tasks | - AI-powered digital colony picking identified a mutant with 19.7% increased lactate production and 77.0% enhanced growth under stress [16] |
| Generative AI | - De novo design of antibody and protein sequences [18]- Creating novel molecular structures with desired properties- Multi-parameter optimization of biologics | - Generates novel, optimized candidate molecules | - Achieved a 78.5% target binding success rate for de novo generated antibody sequences [18]- Demonstrated a tenfold increase in candidate generation [18] |
AI-Driven vs. Traditional Strain Optimization: Experimental Validation
A key area where AI demonstrates significant impact is in microbial strain optimization for developing cell factories. The following case study and data compare an AI-driven approach with a traditional method.
Case Study: AI-Powered Digital Colony Picker (DCP) for Zymomonas mobilis Optimization [16]
- Objective: To identify mutant strains of Z. mobilis with enhanced lactate tolerance and production, a critical bottleneck in traditional bioprocessing.
- AI-Driven Method: An AI-powered Digital Colony Picker (DCP) platform was used. This system uses a microfluidic chip with 16,000 picoliter-scale microchambers to compartmentalize individual cells. AI-driven image analysis dynamically monitored single-cell morphology, proliferation, and metabolic activities in real-time. Target clones were then exported contact-free using a laser-induced bubble technique [16].
- Traditional Method: Traditional colony-based plate assays, which rely on macroscopic measurements of colony size or metabolic indicators. These methods are low-throughput, slow, and unable to address cellular heterogeneity or detect subtle phenotypic advantages [16].
Table 2: Performance Comparison: AI-Driven vs. Traditional Strain Optimization
| Performance Metric | AI-Driven DCP Platform [16] | Traditional Colony Screening [16] |
|---|---|---|
| Throughput | 16,000 addressable microchambers per chip | Limited by plate size (e.g., 96-well to 384-well plates) |
| Resolution | Single-cell, multi-modal phenotyping (growth & metabolism) | Population-level, macroscopic evaluation |
| Screening Speed | Dynamic, real-time monitoring | Delayed feedback (days to weeks) |
| Identified Mutant Performance | 19.7% increase in lactate production77.0% enhancement in growth under 30 g/L lactate stress | Not specified - less efficient at detecting rare phenotypes |
| Key Advantage | Identifies rare phenotypes with spatiotemporal precision; prevents droplet fusion | Well-established, low technical complexity |
Experimental Protocols for AI-Driven Workflows
This protocol outlines the closed-loop workflow for generating and validating fully human HCAbs using generative AI.
- AI Model Training: A generative AI model is trained on a dataset of 9 million Next-Generation Sequencing (NGS)-derived HCAb sequences and extensive public data.
- Sequence Generation: The fine-tuned protein large language model performs de novo generation of novel HCAb sequences.
- AI-Powered Screening:
- An AI Classification Model filters out non-functional HCAb sequences.
- A Multimodal AI Developability Prediction Model assesses critical parameters such as stability, solubility, and aggregation tendency.
- Wet-Lab Validation: Candidates that pass the AI screening are synthesized and tested in in vitro assays. Key performance indicators include binding affinity (measured by IC50), yield (mg/L), and cross-reactivity.
- Closed-Loop Learning: Experimental results from the wet-lab validation are fed back into the AI model to continuously improve its predictive accuracy and design capabilities [18].
This protocol details the use of the Digital Colony Picker for phenotype-based screening of microbial strains.
- Vacuum-Assisted Single-Cell Loading: A microfluidic chip is pre-vacuumed. A single-cell suspension is introduced, and residual air is absorbed by the PDMS layer, facilitating rapid loading of single cells into 16,000 microchambers in under one minute.
- Incubation and Monoclone Formation: The chip is incubated in a temperature-controlled incubator, allowing individual cells to grow into independent microscopic monoclones. Gas-phase isolation between microchambers prevents cross-contamination.
- AI-Powered Identification and Sorting:
- An oil phase is injected into the chip to facilitate droplet collection.
- An AI-driven image recognition system automatically scans and identifies microchambers containing monoclonal colonies based on target phenotypic signatures.
- Contactless Clone Export: The motion platform positions a laser focus at the base of the target microchamber. Using the Laser-Induced Bubble (LIB) technique, a microbubble is generated, propelling the single-clone droplet toward the outlet for collection in a 96-well plate.
- Downstream Validation: Collected clones are cultured and validated for desired metabolic output and growth characteristics under stress conditions [16].
Workflow and Signaling Pathways
The following diagram illustrates the integrated, closed-loop workflow that is characteristic of modern AI-driven biologics discovery, contrasting it with the linear traditional approach.
AI-Driven Biologics Discovery Workflow
The application of these AI technologies has led to the identification of key genes and pathways involved in strain optimization. For instance, the AI-powered DCP platform linked the improved lactate tolerance and production phenotype in Zymomonas mobilis to the overexpression of ZMOp39x027, a canonical outer membrane autotransporter that promotes lactate transport and cell proliferation under stress [16]. The diagram below visualizes this functional discovery.
Functional Pathway of a Key Gene in Strain Optimization
The Scientist's Toolkit: Essential Research Reagent Solutions
The effective implementation of AI in biologics relies on a foundation of robust laboratory technologies and data management systems. The following table details key solutions that enable AI-ready workflows.
Table 3: Essential Research Reagent Solutions for AI-Driven Biologics
| Tool / Solution | Function | Role in AI-Driven Workflows |
|---|---|---|
| Scientific Data Management Platforms (SDMPs) e.g., CDD Vault, Benchling [14] | Centralized platform for organizing structured chemical and biological data. | Provides the critical "AI-ready" foundation by ensuring data is structured, searchable, and interoperable for training ML models [14]. |
| Microfluidic Picoliter Bioreactors [16] | High-throughput, single-cell cultivation and screening platform (e.g., Digital Colony Picker). | Generates high-resolution, single-cell phenotypic data required for training accurate AI/ML models for strain optimization [16]. |
| AI-Ready Assay Kits | Standardized kits for generating bioactivity data (e.g., IC50, titer) [14]. | Produces clean, consistent, and structured experimental data that can be directly linked to chemical structures or biological sequences for SAR modeling [14]. |
| Automated Liquid Handlers e.g., Tecan Veya [12] | Automates repetitive pipetting and assay setup tasks. | Increases experimental reproducibility and throughput, while automatically capturing rich metadata essential for AI model training and validation [12]. |
| Generative AI Protein Models e.g., Harbour BioMed's AI HCAb Model [18] | Fine-tuned large language models for de novo protein and antibody sequence generation. | Serves as the core engine for designing novel biologic candidates, moving discovery from blind screening to intelligent, target-aware design [18]. |
| (Rac)-Tanomastat | (Rac)-Tanomastat, MF:C23H19ClO3S, MW:410.9 g/mol | Chemical Reagent |
| IDH-C227 | IDH-C227, MF:C30H31FN4O2, MW:498.6 g/mol | Chemical Reagent |
The integration of machine learning, deep learning, and generative AI into biologics discovery is no longer a speculative future but a present-day reality that is yielding measurable gains. As evidenced by the experimental data, AI-driven methodologies for strain optimization and antibody discovery are demonstrating superior performance in terms of speed, success rate, and the ability to identify superior candidates compared to traditional methods. The continued evolution of these technologies, supported by robust data management and automated experimental platforms, promises to further accelerate the development of next-generation biologics.
The integration of artificial intelligence into scientific research and drug development represents not merely an incremental improvement but a fundamental paradigm shift in how we approach validation and optimization. For decades, traditional methods relying on manual processes, established statistical techniques, and hypothesis-driven experimentation have formed the bedrock of scientific validation. While these approaches have yielded tremendous advances, they increasingly struggle with the complexity, volume, and high-dimensional nature of modern scientific challenges, particularly in fields like strain optimization and drug development. The emergence of AI-driven approaches, especially machine learning and active learning frameworks, has created a new battlefield where the very definition of validation is being rewritten.
This comparison guide objectively examines the performance characteristics of traditional validation methodologies against emerging AI-driven approaches, with particular focus on their application in scientific domains requiring rigorous validation. We analyze quantitative experimental data across multiple dimensions including efficiency, accuracy, scalability, and resource utilization. The evidence reveals a complex landscape where AI-driven methods demonstrate transformative potential in handling high-dimensional optimization problems, while traditional approaches maintain advantages in interpretability and established regulatory acceptance. Understanding this battlefield is crucial for researchers, scientists, and drug development professionals navigating the transition toward increasingly AI-augmented research paradigms.
Quantitative Performance Comparison
The transition from traditional to AI-driven methods can be quantitatively assessed across multiple performance dimensions. Experimental data from controlled studies reveals significant differences in throughput, accuracy, and resource utilization between these approaches.
Table 1: Performance Metrics Comparison Between Traditional and AI-Driven Methods
| Performance Metric | Traditional Methods | AI-Driven Methods | Experimental Context |
|---|---|---|---|
| Data Processing Throughput | Baseline (1.0x) | 6.03-fold increase [10] | Medical data cleaning [10] |
| Error Rate Reduction | 54.67% baseline | 8.48% (6.44-fold improvement) [10] | Medical data cleaning [10] |
| False Positive Reduction | Baseline | 15.48-fold decrease [10] | Clinical trial data query management [10] |
| Problem Dimensionality Handling | ~100 dimensions [19] | Up to 2,000 dimensions [19] | Complex system optimization [19] |
| Data Efficiency | Large datasets required [19] | Effective with limited data (~200 points) [19] | Optimization with expensive data labeling [19] |
| Economic Impact | Baseline | $5.1M potential savings [10] | Phase III oncology trial [10] |
| Timeline Acceleration | Baseline | 33% reduction in database lock [10] | Clinical trial operations [10] |
Table 2: Methodological Characteristics Across Domains
| Characteristic | Traditional Validation | AI-Driven Validation | Key Differentiators |
|---|---|---|---|
| Core Philosophy | Trial-and-error, hypothesis-driven [19] | Data-driven, iterative learning [19] | AI uses closed-loop experimentation [19] |
| Primary Strengths | Interpretable, established regulatory pathways [10] | Handles high-dimensional, nonlinear systems [19] | AI excels where traditional assumptions break down [20] |
| Validation Approach | Independent, identically distributed data [20] | Spatial/smoothness regularity assumptions [20] | AI methods better for spatial prediction tasks [20] |
| Implementation Complexity | Lower technical barrier | High infrastructure and skills requirements [21] | 60% of engineering firms lack AI strategy [21] |
| Resource Requirements | Human-intensive, time-consuming [22] | Computational-intensive, automated [22] | Systematic reviews reduced from 67 weeks to 2 weeks [22] |
The quantitative evidence demonstrates that AI-driven methods can deliver substantial improvements in processing efficiency and accuracy while handling significantly more complex problems. In clinical data cleaning, AI-assistance increased throughput by over 6-fold while reducing errors by a similar magnitude [10]. For optimization tasks, AI methods successfully scaled to problems with 2,000 dimensions, far beyond the approximately 100-dimension limit of traditional approaches [19]. The economic implications are substantial, with AI-driven clinical trial management potentially saving millions of dollars through accelerated timelines and reduced manual effort [10].
Experimental Protocols and Methodologies
Traditional Validation Methods
Traditional validation methodologies typically follow established protocols with manual or semi-automated processes. In clinical data cleaning, the conventional approach involves medical reviewers manually examining case report forms, adverse event narratives, and laboratory values using spreadsheet-based workflows [10]. This process requires specialized expertise to identify clinically meaningful discrepancies while maintaining regulatory compliance. The manual approach suffers from inconsistent application of clinical judgment across reviewers, inability to scale with increasing data volumes, and susceptibility to human error during repetitive tasks [10].
In spatial prediction tasks, traditional validation uses hold-out validation data assuming independence and identical distribution between validation and test data [20]. This approach applies tried-and-true validation methods to determine trust in predictions for weather forecasting or air pollution estimation [20]. However, MIT researchers demonstrated these popular validation methods can fail substantially for spatial prediction tasks because they make inappropriate assumptions about how validation data and prediction data are related [20]. The fundamental limitation is that traditional methods assume data points are independent when in spatial applications they often are not.
AI-Driven Validation Protocols
AI-driven approaches employ fundamentally different validation methodologies designed for complex, high-dimensional problems:
Active Optimization Framework: The DANTE (Deep Active Optimization with Neural-Surrogate-Guided Tree Exploration) pipeline represents an advanced AI-driven approach for complex system optimization [19]. This method begins with a limited initial database (approximately 200 points) used to train a deep neural network surrogate model [19]. The system then employs a tree search modulated by a data-driven Upper Confidence Bound (DUCB) and the deep neural network to explore the search space through backpropagation methods [19]. Key innovations include conditional selection (preventing value deterioration during search) and local backpropagation (enabling escape from local optima) [19]. Top candidates are sampled and evaluated using validation sources, with newly labeled data fed back into the database in an iterative closed loop [19].
Spatial Validation Technique: MIT researchers developed a specialized validation approach for spatial prediction problems that assumes validation and test data vary smoothly in space rather than being independent and identically distributed [20]. This regularity assumption is appropriate for many spatial processes and addresses the fundamental limitations of traditional validation for problems like weather forecasting or air pollution mapping [20]. The technique automatically estimates predictor accuracy for target locations based on this spatial smoothness principle.
AI-Assisted Clinical Data Cleaning: The Octozi platform exemplifies AI-human collaboration, combining large language models with domain-specific heuristics and deterministic clinical algorithms [10]. This hybrid architecture processes both structured and unstructured data, identifies discrepancies invisible to traditional methods, integrates external medical knowledge for clinical reasoning, and contextualizes data within the patient's journey [10]. The system maintains human oversight while dramatically improving efficiency through automation of routine aspects.
Visualization of Methodologies
Core Philosophical Differences
Core Philosophical Differences
AI Active Optimization Pipeline
AI Active Optimization Pipeline
Experimental Validation Workflow
Experimental Validation Workflow
The Scientist's Toolkit: Essential Research Reagents and Solutions
Implementation of both traditional and AI-driven validation methods requires specific technical resources and infrastructure. The following table details key solutions essential for conducting comparative validation studies.
Table 3: Essential Research Reagents and Solutions for Validation Studies
| Tool/Resource | Function/Purpose | Application Context |
|---|---|---|
| Synthetic Dataset Generation | Creates realistic while anonymized experimental data from original clinical databases [10] | Controlled studies comparing method performance [10] |
| Deep Neural Network Surrogates | Approximates complex system behavior using limited initial data points [19] | Active optimization pipelines for high-dimensional problems [19] |
| Data-Centric AI Platforms | Implements hybrid AI architectures combining LLMs with domain-specific algorithms [10] [23] | Healthcare data quality improvement across multiple dimensions [23] |
| Spatial Validation Framework | Implements spatial regularity assumptions for prediction validation [20] | Weather forecasting, pollution mapping, spatial prediction tasks [20] |
| Tree Search with DUCB | Modulates exploration-exploitation tradeoff using data-driven upper confidence bounds [19] | Neural-surrogate-guided exploration in complex search spaces [19] |
| Analytical Quality by Design (AQbD) | Systematic approach for analytical method development using risk assessment [24] | HPLC method optimization and validation in pharmaceutical analysis [24] |
| NCGC00378430 | NCGC00378430, MF:C22H23N3O5S, MW:441.5 g/mol | Chemical Reagent |
| Fgfr4-IN-12 | Fgfr4-IN-12, MF:C34H32Cl2N4O6, MW:663.5 g/mol | Chemical Reagent |
The comparative analysis reveals a nuanced battlefield where AI-driven methods demonstrate clear advantages in processing efficiency, scalability to complex problems, and economic impact, while traditional approaches maintain strengths in interpretability and established regulatory acceptance. The experimental evidence indicates that AI-driven validation can achieve 6-fold improvements in throughput and accuracy while handling problems an order of magnitude more complex than traditional approaches [10] [19]. However, successful implementation requires addressing significant challenges including data infrastructure requirements, workforce skills gaps, and integration with existing workflows [21].
The future of validation in scientific research and drug development likely lies in hybrid approaches that leverage the strengths of both paradigms. AI-driven methods excel at processing high-dimensional data and identifying complex patterns, while traditional approaches provide critical oversight, interpretability, and regulatory compliance. As AI validation techniques mature and address current limitations around transparency and integration, they are poised to become increasingly dominant in the validation landscape, potentially reducing traditional systematic review timelines from 67 weeks to just 2 weeks in some applications [22]. For researchers and drug development professionals, understanding this evolving battlefield is essential for navigating the transition and selecting the appropriate validation methodology for specific scientific challenges.
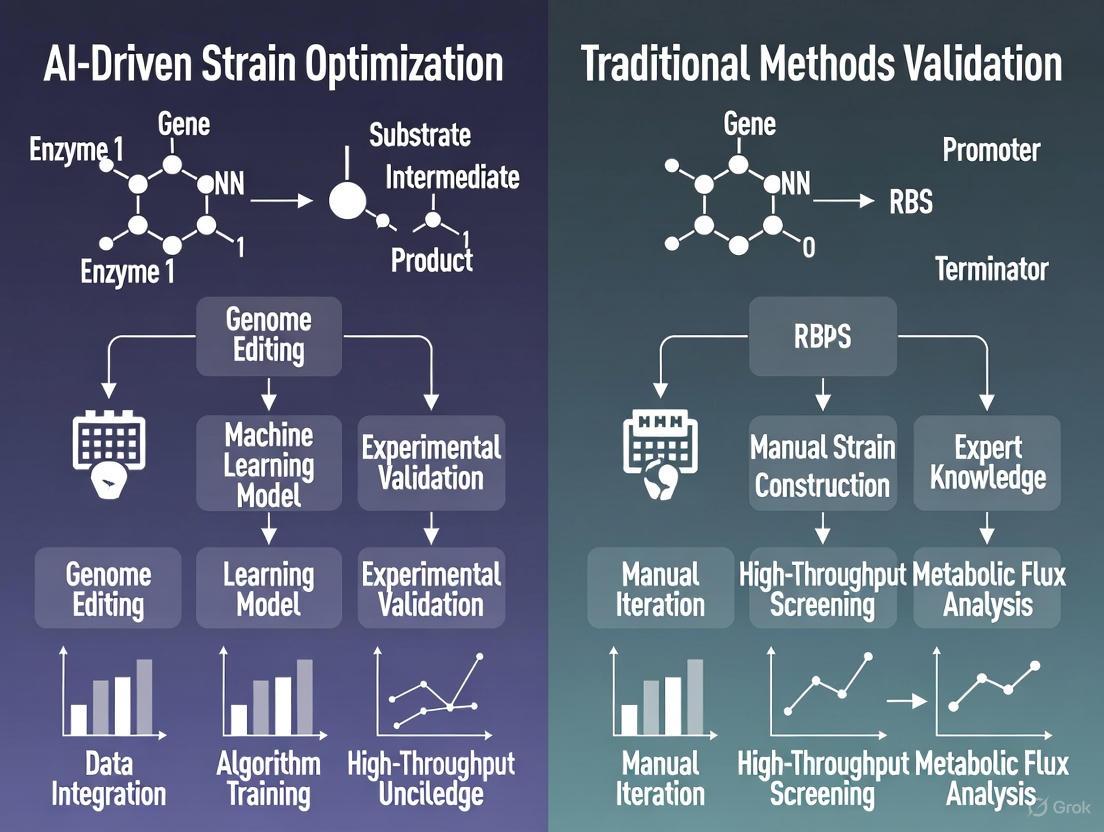
Building the AI-Driven Strain Optimization Workflow: A Methodological Deep Dive
The advent of artificial intelligence (AI) in biological research has fundamentally shifted the paradigm of strain optimization and drug discovery. While algorithmic advancements often capture attention, the quality, structure, and accessibility of the underlying biological data ultimately determine the success of AI initiatives. AI-ready data is characterized by its adherence to FAIR principles (Findable, Accessible, Interoperable, Reusable), comprehensive metadata, and suitability for machine learning applications [25]. In the context of strain optimization, the contrast between traditional methods and AI-driven approaches is stark: where traditional techniques rely on sequential, labor-intensive experimentation often limited by throughput and human bias, AI-powered workflows can navigate vast biological design spaces with unprecedented efficiency. However, this capability is entirely dependent on a robust foundation of meticulously curated data. This guide examines the core methodologies, technological platforms, and data curation practices that enable effective AI-driven strain optimization, providing researchers with a framework for evaluating and implementing these advanced approaches.
Comparative Analysis: Traditional vs. AI-Driven Strain Optimization
The transition from traditional to AI-driven methods represents more than just technological augmentation; it constitutes a fundamental reimagining of the biological engineering workflow. The table below summarizes the key distinctions across critical parameters.
Table 1: Performance Comparison of Strain Optimization Methods
| Parameter | Traditional Methods | AI-Driven Methods | Experimental Support |
|---|---|---|---|
| Throughput | Low to moderate (manual colony picking, plate-based assays) | Very high (AI-powered digital colony picker: 16,000 clones screened at single-cell resolution) | AI-powered Digital Colony Picker (DCP) screens 16,000 picoliter-scale microchambers [16]. |
| Screening Resolution | Population-level averages, masking cellular heterogeneity | Single-cell resolution, capturing dynamic behaviors and rare phenotypes | DCP provides "single-cell-resolved, contactless screening" and identifies subtle phenotypic advantages [16]. |
| Cycle Time | Weeks to months per Design-Build-Test-Learn (DBTL) cycle | Highly accelerated (e.g., 4 rounds of enzyme engineering completed in 4 weeks) | Autonomous enzyme engineering platform completed 4 rounds of optimization in 4 weeks [26]. |
| Data Dependency & Quality | Relies on experimental intuition; limited, often unstructured data | Requires large, structured, AI-ready datasets with rich metadata for model training | Success depends on "high-quality, standardized, and comprehensive metadata" [27]. |
| Variant Construction Efficiency | Site-directed mutagenesis with need for sequence verification (~95% accuracy) | HiFi-assembly mutagenesis with ~95% accuracy but no need for intermediate verification, enabling continuous workflow | Automated biofoundry uses a high-fidelity method that "eliminated the need for sequence verification" for uninterrupted workflow [26]. |
| Optimization Outcome | Incremental improvements; limited exploration of sequence space | Large functional leaps (e.g., 26-fold activity improvement, 19.7% increased production) | DCP identified a Zymomonas mobilis mutant with "19.7% increased lactate production and 77.0% enhanced growth" [16]. Autonomous engineering achieved "26-fold improvement in activity" [26]. |
Experimental Protocols for AI-Driven Strain Optimization
Protocol 1: Autonomous Enzyme Engineering on a Biofoundry
This protocol outlines the end-to-end automated workflow for engineering improved enzymes, as demonstrated with halide methyltransferase (AtHMT) and phytase (YmPhytase) [26].
Design Phase:
- Input: Provide the wild-type protein sequence and a defined objective (e.g., "improve ethyltransferase activity").
- Variant Generation: Use a combination of a protein Large Language Model (LLM) like ESM-2 and an epistasis model (EVmutation) to generate a diverse, high-quality initial library of variant sequences (e.g., 180 variants). The LLM predicts amino acid likelihoods, while the epistasis model incorporates evolutionary constraints from homologs.
Build Phase:
- Library Construction: An automated biological foundry (e.g., the Illinois Biological Foundry for Advanced Biomanufacturing, iBioFAB) executes a high-fidelity (HiFi) DNA assembly-based mutagenesis method.
- Cloning & Transformation: The system performs mutagenesis PCR, DNA assembly, and high-throughput microbial transformation in 96-well plates without intermediate sequence verification, ensuring a continuous and rapid workflow.
Test Phase:
- Protein Expression & Assay: Automated modules carry out colony picking, protein expression in a 96-well format, and a functional enzyme assay tailored to the fitness objective (e.g., measuring halide methyltransferase or phytase activity).
- Data Capture: The instrument records quantitative fitness data for every variant, ensuring all experimental conditions and results are captured as structured metadata.
Learn Phase:
- Model Training: A machine learning model (e.g., a low-N model capable of learning from sparse data) is trained on the collected variant-fitness data.
- Next-Proposal: The trained model predicts the fitness of a vast number of unseen variants in silico. The most promising candidates for the next cycle are selected, combining predicted high fitness and sequence diversity.
This DBTL cycle is repeated autonomously for multiple rounds (e.g., 4 rounds) until the performance objective is met.
AI-Driven Enzyme Engineering Workflow
Protocol 2: High-Throughput Phenotypic Screening with an AI-Powered Digital Colony Picker
This protocol details the use of microfluidics and AI for screening microbial strains based on growth and metabolic phenotypes at single-cell resolution [16].
Chip Preparation and Cell Loading:
- Utilize a microfluidic chip containing thousands of addressable picoliter-scale microchambers.
- Introduce a diluted single-cell suspension of the pre-engineered microbial library (e.g., Zymomonas mobilis mutants) into the chip via a vacuum-assisted process. The cell concentration is optimized (e.g., ~1×10ⶠcells/mL) to ensure a high probability of single-cell occupancy in each microchamber based on Poisson distribution.
Incubation and Dynamic Monitoring:
- Incubate the chip under controlled conditions (e.g., temperature, gas) to allow individual cells to grow into microscopic monoclonal colonies.
- Optionally, use the system's liquid replacement capability to exchange culture media or introduce stressors (e.g., high lactate concentration) during incubation.
AI-Powered Image Analysis and Sorting:
- Acquire time-lapse images of the microchambers throughout the incubation period.
- An AI-driven image analysis algorithm dynamically monitors single-cell morphology, proliferation rates, and metabolic activities (if fluorescent reporters are used) in each microchamber.
- Based on the target phenotype (e.g., rapid growth under lactate stress), the system identifies and ranks the top-performing monoclones.
Contactless Clone Export:
- For each selected clone, the system positions a laser focus at the base of its microchamber.
- The Laser-Induced Bubble (LIB) technique generates a microbubble that propels the single-clone droplet out of the microchamber and into a shared channel.
- A capillary tube at the outlet transfers the exported droplets into a 96-well collection plate for downstream validation and cultivation.
Digital Colony Picker Screening Process
Protocol 3: AI-Guided Probiotic Strain Selection and Metabolite Prediction
This protocol leverages AI to accelerate the discovery of probiotic strains and their beneficial metabolites, moving beyond traditional in vitro assays [28].
Data Compilation and Curation:
- Genomic Data: Collect whole-genome sequences of candidate probiotic strains (e.g., lactobacilli, bifidobacteria).
- Functional Data: Assemble existing in vitro data on functional properties (e.g., acid resistance, bile salt hydrolase activity) and associate it with genomic features.
- Metabolomic Data: Integrate data on metabolites produced by known probiotics (e.g., antimicrobial peptides, exopolysaccharides).
Model Training and Validation:
- Train machine learning (ML) models, such as Random Forest or Support Vector Machines, on the curated datasets.
- For strain screening, use genomic features (e.g., presence of specific genes like tRNA patterns) to predict functional properties with high accuracy (e.g., >97% accuracy in bacterial identification).
- For metabolite prediction, train models to link genomic signatures with the production of specific bioactive compounds.
In Silico Screening and Prioritization:
- Input the genomic sequences of novel, uncharacterized bacterial isolates into the trained models.
- The models output predictions for desired functional traits (e.g., gut adhesion potential, antimicrobial production) and flag the most promising candidate strains for further experimental validation.
Experimental Validation:
- The shortlisted strains are progressed to in vitro and in vivo testing, significantly increasing the hit rate compared to random, non-AI-guided screening.
Essential Research Reagent Solutions for AI-Ready Workflows
The implementation of advanced AI-driven protocols requires a suite of specialized reagents and platforms. The following table details key solutions that form the foundation of these workflows.
Table 2: Key Research Reagent Solutions for AI-Driven Strain Optimization
| Solution / Platform | Function | Application in AI-Driven Workflow |
|---|---|---|
| Automated Biofoundry (e.g., iBioFAB) | Integrated robotic system for executing biological protocols end-to-end. | Automates the entire "Build" and "Test" phase of the DBTL cycle, enabling high-throughput, reproducible experimentation without human intervention [26]. |
| Microfluidic Chips (Picoliter Microchambers) | Miniaturized bioreactors for single-cell isolation and cultivation. | Provides the physical platform for high-resolution phenotypic screening in the Digital Colony Picker, allowing dynamic monitoring of thousands of individual clones [16]. |
| AI-Ready Biospecimen Datasets (e.g., Visionaire) | Deeply curated biospecimen data pairing digital pathology slides with clinical, molecular, and tissue data. | Provides the high-quality, context-rich data necessary for training robust AI models in fields like computational pathology and biomarker discovery [29]. |
| Controlled Vocabularies & Ontologies (e.g., OBO Foundry) | Standardized terminologies for describing biological entities and experiments. | Ensures data interoperability and reusability (the "I" and "R" in FAIR), which is critical for building large, machine-readable datasets for AI [25] [27]. |
| Protein Large Language Models (e.g., ESM-2) | AI models trained on global protein sequence databases. | Used in the "Design" phase to intelligently propose functional protein variants by learning evolutionary constraints and patterns [26]. |
| Cell-Free Protein Synthesis (CFPS) Systems | In vitro transcription-translation system for rapid protein production. | Serves as a versatile and automation-friendly "Test" platform for high-throughput screening of enzyme activity and protein expression without the need for live cells [30]. |
The comparative data and protocols presented in this guide unequivocally demonstrate the superior performance of AI-driven strain optimization over traditional methods. The key differentiator is not the AI algorithms themselves, but the quality and structure of the data upon which they are built. Successful implementation requires a holistic approach that integrates advanced hardware (biofoundries, microfluidic chips), intelligent software (LLMs, ML models), and, most critically, a commitment to generating and curating AI-ready biological data with rich metadata and standardized ontologies. As the field evolves, the institutions and researchers who prioritize building robust, FAIR-compliant data foundations will be best positioned to leverage the full power of AI, accelerating the discovery of novel therapeutics, sustainable materials, and high-performance industrial microbes.
Target Identification and Validation with AI-Driven Data Mining
The following table summarizes the core performance differences between AI-driven and traditional methods for target identification and validation, based on current industry data and research.
| Performance Metric | Traditional Methods | AI-Driven Methods | Supporting Data / Case Study |
|---|---|---|---|
| Initial Timeline | 3-6 years [31] | ~18 months [31] [32] | Insilico Medicine's TNIK inhibitor for IPF [31] [32] |
| Target Identification | Manual literature review, hypothesis-driven | NLP analysis of millions of papers, multi-omics data integration [31] [33] | AI platforms can process vast datasets to uncover hidden patterns [33] [34] |
| Cost Implications | High (Part of a >$1B total drug development cost) [34] | Significant reduction in early R&D costs [34] | AI reduces resource-intensive false starts [33] |
| Data Utilization | Limited by human scale; structured data only | Multimodal analysis (genomics, imaging, clinical records) [31] [35] | Owkin uses clinical, omics, and imaging data for target discovery [35] |
| Virtual Screening Speed | Days to weeks for limited libraries | Millions of compounds screened in days or hours [34] | Atomwise identified Ebola drug candidates in <1 day [34] |
| Validation Robustness | In-vitro/in-vivo models with potential translation issues | In-silico simulation and digital twins for predictive validation [34] | AI models can predict toxicity and efficacy before wet-lab work [34] |
Target identification and validation represents the foundational first step in the drug discovery pipeline, where biological targets (e.g., proteins, genes) associated with a disease are identified and their therapeutic relevance confirmed. For decades, this process has relied on traditional methods—labor-intensive, sequential workflows involving high-throughput screening, manual literature review, and trial-and-error experiments in the laboratory [31] [34]. These approaches are constrained by high attrition rates, with an estimated 90% of oncology drugs failing during clinical development [31].
In contrast, AI-driven data mining represents a paradigm shift. It leverages machine learning (ML), deep learning (DL), and natural language processing (NLP) to integrate and analyze massive, multimodal datasets. This includes genomic profiles, proteomics, scientific literature, and clinical records to generate predictive models that accelerate the identification of druggable targets and strengthen their validation [31] [33]. This comparison guide objectively assesses the performance of these two approaches within the broader context of modern drug development.
Detailed Performance Comparison
Speed and Efficiency in Early Discovery
The acceleration of early-stage discovery is one of AI's most significant advantages.
- Traditional Workflow: This process is inherently linear and slow. It can take 3 to 6 years to move from target identification to a preclinical candidate, consuming vast resources before a molecule even enters clinical trials [31] [33].
- AI-Driven Workflow: AI compresses these timelines dramatically. A landmark case is Insilico Medicine's development of a novel TNIK inhibitor for idiopathic pulmonary fibrosis (IPF). Using its generative AI platform, the company identified a drug candidate and advanced it to Phase 2 trials in approximately 18 months, a fraction of the traditional timeline [31] [32]. Similarly, Atomwise used its AI-powered virtual screening to identify two promising drug candidates for Ebola in less than a day [34].
Accuracy and Predictive Power
AI enhances the predictive accuracy of target validation by uncovering complex, non-obvious patterns.
- Target Identification: Traditional methods rely heavily on established knowledge and can miss novel or complex target-disease relationships. AI, particularly NLP, can mine millions of scientific publications and databases to surface previously overlooked connections and novel targets [31] [33]. For example, BenevolentAI used its platform to predict novel targets in glioblastoma by integrating transcriptomic and clinical data [31].
- Target Validation and Safety: AI improves validation by predicting a target's role in disease biology and potential off-target effects. Machine learning models can analyze biological data to simulate drug behavior in the human body, forecasting toxicity and efficacy issues early. This not only saves resources but also reduces the reliance on animal models in the preclinical stage [34].
Cost and Resource Implications
The financial burden of traditional drug discovery is immense, with the total cost of bringing a single drug to market estimated at over $1 billion [34]. A significant portion of this cost is attributed to early-stage failures. AI addresses this bottleneck by de-risking the initial phases. By focusing resources on targets and compounds with a higher computationally-derived probability of success, companies can lower overall R&D spend and reduce the cost of false starts [33] [34].
Experimental Protocols and Methodologies
Standard Traditional Workflow for Target Validation
The following diagram illustrates the sequential, hypothesis-driven process of traditional target validation.
Key Steps Explained:
- Hypothesis Generation: Researchers manually review existing scientific literature to form an initial hypothesis about a potential target's link to a disease [31].
- Genetic Association Studies: Techniques like CRISPR or siRNA are used to knock out or knock down the target gene in cellular models to observe phenotypic changes and confirm its functional role in the disease pathway [31].
- Protein Expression Analysis: Methods like Western Blot or Immunohistochemistry (IHC) are used to verify the presence and levels of the target protein in diseased versus healthy tissues [31].
- In-vitro Functional Assays: Cell-based models are used to study the biological function of the target and the initial effects of its modulation [31] [12].
- In-vivo Validation: Animal models are employed to confirm the target's physiological relevance and therapeutic potential in a complex living system [31].
AI-Enhanced Workflow for Target Identification & Validation
The following diagram depicts the iterative, data-centric workflow of AI-driven target discovery and validation.
Key Steps Explained:
- Multimodal Data Aggregation: Diverse datasets are collected, including genomics (from sources like TCGA), transcriptomics, proteomics, scientific literature (via NLP), real-world evidence, and medical imaging [31] [34] [35].
- AI/ML Data Mining & Analysis: Machine learning and deep learning algorithms (e.g., convolutional neural networks, generative models) are applied to this integrated data to uncover hidden patterns, predict novel target-disease associations, and prioritize the most promising targets [31] [34].
- In-silico Target Validation: AI models simulate disease biology and the impact of target modulation. This includes predicting protein-ligand binding affinities (e.g., with tools like AlphaFold), off-target interactions, and toxicity profiles computationally before any lab work begins [34] [35].
- Wet-Lab Experimental Validation: The top computationally-validated targets are moved into focused, hypothesis-driven laboratory experiments (e.g., automated high-throughput assays, 3D cell culture models) for biological confirmation [12] [34]. This step is more efficient as AI has already de-risked the target selection.
- AI Model Refinement: Results from wet-lab experiments are fed back into the AI models in an iterative loop, continuously improving the algorithm's accuracy and predictive power for future discovery cycles [33].
The Scientist's Toolkit: Key Platforms and Reagents
The adoption of AI-driven discovery relies on a new generation of computational tools and supported laboratory technologies. The table below details essential solutions for implementing these workflows.
| Tool / Solution | Provider / Example | Primary Function in Target ID/V | Key Application Note |
|---|---|---|---|
| AI Target Prediction Platform | Deep Intelligent Pharma, Insilico Medicine [35] | End-to-end AI-native target identification and validation via multi-agent workflows and natural-language processing. | Deep Intelligent Pharma reported up to 1000% efficiency gains in R&D automation benchmarks [35]. |
| Structure Prediction AI | Isomorphic Labs, AlphaFold [34] [35] | Predicts 3D protein structures with high accuracy, illuminating binding sites and informing target feasibility. | Critical for understanding target mechanism and enabling structure-based drug design [34]. |
| Virtual Screening Suite | Atomwise [34] [35] | Uses deep learning to predict protein-ligand interactions and rapidly screen massive virtual compound libraries. | Identified Ebola drug candidates in under 24 hours; ideal for hit-finding against a validated target [34]. |
| Multimodal Data Analysis Platform | Owkin [35], Sonrai Analytics [12] | Integrates clinical, omics, and imaging data to identify novel targets and biomarkers from real-world evidence. | Uses federated learning to collaborate across institutions without sharing raw patient data, preserving privacy [12] [35]. |
| Automated Cell Culture System | mo:re MO:BOT Platform [12] | Automates 3D cell culture (e.g., organoids) for highly reproducible, human-relevant validation assays. | Produces consistent, biologically relevant tissue models for more predictive efficacy and toxicity testing [12]. |
| Automated Protein Expression | Nuclera eProtein Discovery System [12] | Automates protein expression and purification from DNA to soluble protein in under 48 hours. | Accelerates the production of target proteins and reagents needed for downstream functional and structural studies [12]. |
| (R)-ND-336 | (R)-ND-336, MF:C16H17NO3S2, MW:335.4 g/mol | Chemical Reagent | Bench Chemicals |
| Lnp lipid II-10 | Lnp lipid II-10, MF:C60H118N2O5, MW:947.6 g/mol | Chemical Reagent | Bench Chemicals |
The comparative data and experimental evidence clearly demonstrate that AI-driven data mining offers a superior performance profile for target identification and validation compared to traditional methods. The key advantages are unprecedented speed, enhanced predictive accuracy, and significant cost reduction in the critical early stages of drug discovery.
However, AI is not a replacement for biological expertise and laboratory validation. Instead, the most effective modern R&D strategy is a synergistic loop, where AI rapidly generates high-probability hypotheses from big data, and traditional lab methods provide the essential biological confirmation. As the field evolves, the integration of explainable AI and federated learning will further solidify this hybrid approach, ultimately accelerating the delivery of novel therapies to patients.
Generative AI and Molecular Modeling for Novel Strain Design
The field of microbial strain design is undergoing a profound transformation, moving from traditional trial-and-error methods to a precision engineering discipline powered by generative artificial intelligence (AI) and molecular modeling. Traditional strain development relies heavily on iterative laboratory experiments, such as random mutagenesis and selective screening, processes that are often time-consuming, costly, and limited in their ability to predict complex cellular behaviors [36]. In contrast, AI-driven approaches leverage machine learning (ML), deep learning (DL), and generative models to create in-silico representations of biological systems. These digital counterparts enable researchers to simulate genetic modifications, predict phenotypic outcomes, and explore a vastly larger design space before any wet-lab experimentation begins [19] [36].
This paradigm shift aligns with the broader 3Rs principle (Replace, Reduce, Refine) in preclinical research, aiming to replace animal testing, reduce experimental costs, and refine biological hypotheses through computational power [36]. The validation of AI-driven strain optimization against traditional methods is not merely a technical comparison but a fundamental re-evaluation of how biological discovery is conducted. By integrating multi-omics data, molecular dynamics simulations, and AI-powered design, researchers can now generate novel microbial strains with optimized metabolic pathways for pharmaceutical production, biofuel synthesis, and therapeutic applications with unprecedented speed and precision [37] [38].
Comparative Analysis: Generative AI vs. Traditional Methods
The following comparison quantitatively assesses the performance of generative AI-driven approaches against traditional methods across critical parameters in strain design and optimization.
Table 1: Performance comparison of generative AI and traditional strain design methods
| Performance Metric | Traditional Methods | Generative AI Methods | Experimental Validation |
|---|---|---|---|
| Design Space Exploration | Limited to known variants and random mutagenesis; low diversity [36] | Explores 10-100x more sequence space; generates novel structures [39] [11] | AI-designed antibodies (BoltzGen) show high affinity for 26 therapeutically relevant targets [11] |
| Development Timeline | Months to years for iterative design-build-test cycles [40] [36] | 50-80% reduction in initial discovery phase [40] | Novel antibiotic candidates (e.g., NG1) designed and validated in vivo within a significantly shortened timeline [39] |
| Success Rate & Optimization | Low hit rates; suboptimal due to screening bottlenecks [36] | 10-20% higher binding affinity; superior solution quality [19] [41] | IDOLpro generates ligands with 10-20% higher binding affinity than next-best method [41] |
| Resource Utilization | High cost for experimental materials and animal models [36] | Up to 100x more cost-efficient for initial screening [41] | AI-driven virtual screens are >100x faster and less expensive than exhaustive database screening [41] |
| Handling of Complexity | Struggles with multi-objective, non-linear optimization [19] | Excels in high-dimensional (up to 2000D), non-linear spaces [19] | DANTE algorithm finds superior solutions in problems with up to 2,000 dimensions [19] |
Experimental Protocols for AI-Driven Strain Design
Generative AI Workflow for Molecular Design
This protocol outlines the process for using generative AI to design novel protein binders, as exemplified by the BoltzGen model [11].
- Problem Formulation and Target Selection: Define the biological target (e.g., a specific bacterial enzyme or viral surface protein). For a rigorous test, include targets classified as "undruggable" or those with structures dissimilar to training data.
- Model Selection and Configuration: Employ a unified generative model capable of both structure prediction and protein design, such as BoltzGen. Configure the model with built-in biophysical constraints (e.g., folding stability, solubility) informed by wet-lab expertise to ensure generated proteins are functional and physically plausible.
- In-silico Generation: Execute the model to generate a vast library of candidate protein sequences (e.g., millions of variants) de novo from scratch.
- Computational Screening: Use predictive models to rank candidates based on desired properties, such as predicted binding affinity to the target, specificity, and synthetic accessibility.
- Downstream Validation: Synthesize the top-ranking candidates (e.g., 10-100) for experimental validation. This involves:
- In-vitro binding assays (e.g., Surface Plasmon Resonance) to confirm affinity.
- Structural biology techniques (e.g., X-ray crystallography) to verify the predicted binding mode.
- In-vivo efficacy testing in relevant animal models, as demonstrated for the AI-discovered antibiotic NG1 against drug-resistant gonorrhea in a mouse model [39].
Deep Active Optimization for High-Dimensional Problems
This protocol details the use of the DANTE pipeline for optimizing complex systems with limited data, a common scenario in strain engineering [19].
- Initial Data Collection: Assemble a small, initial dataset (e.g., 100-200 data points) of labeled examples. This could be historical data on strain performance (e.g., yield, growth rate) under different genetic or environmental conditions.
- Deep Neural Surrogate Training: Train a deep neural network (DNN) on the initial dataset to act as a surrogate model, approximating the complex, non-linear relationship between input parameters (e.g., genetic modifications) and the output objective (e.g., metabolite production).
- Neural-Surrogate-Guided Tree Exploration (NTE):
- Conditional Selection: The algorithm starts from a "root" node (a known data point) and stochastically expands to generate new candidate solutions ("leaf" nodes). A leaf node with a higher Data-driven Upper Confidence Bound (DUCB) value than the root becomes the new root for the next iteration, preventing value deterioration.
- Stochastic Rollout & Local Backpropagation: The algorithm explores the region around the new root. Instead of updating the entire search path (as in classic tree search), only the visitation counts and values between the root and the selected leaf are updated. This creates a local gradient that helps the algorithm escape local optima.
- Iterative Sampling and Model Refinement: The top candidates identified by the NTE process are selected (batch size ≤20), evaluated using the real-world system (e.g., a lab assay), and the new data is fed back into the database to retrain and improve the DNN surrogate. This active learning loop continues until performance converges.
Diagram: Workflow for Deep Active Optimization (DANTE)
Multi-Objective Optimization with Differentiable Scoring
This protocol is based on the IDOLpro platform, which uses diffusion models guided by multiple objectives for structure-based drug design [41].
- Objective Definition: Define multiple, often competing, physicochemical objectives for the ideal molecule. For a microbial enzyme, this could include binding affinity to a substrate, thermodynamic stability (ΔG), and synthetic accessibility score (SAS).
- Model Setup: Implement a diffusion model, such as a conditional denoising diffusion probabilistic model (DDPM), where the latent variables can be influenced by differentiable scoring functions representing each objective.
- Guided Generation: During the reverse diffusion process (where noise is iteratively removed to form a molecule), guide the latent variables using gradient signals from the scoring functions. This steers the generation towards regions of chemical space that optimize the plurality of target properties.
- Pareto Front Analysis: Analyze the generated library of molecules to identify the Pareto front—the set of candidates where no single objective can be improved without worsening another. This allows researchers to select the best compromise solution for their specific needs.
The Scientist's Toolkit: Essential Research Reagents and Solutions
Successful implementation of AI-driven strain design relies on a suite of computational and biological tools. The following table details key resources mentioned in the cited experimental work.
Table 2: Key research reagents and solutions for AI-driven strain design
| Tool Name / Category | Function in Research | Specific Application Example |
|---|---|---|
| Generative AI Models | De novo generation of novel molecular structures (proteins, ligands). | BoltzGen: Unified structure prediction and protein binder generation [11]. IDOLpro: Diffusion model for multi-objective ligand design [41]. GANs/VAEs: Generate molecular structures with optimized properties [40]. |
| Active Optimization Algorithms | Finds optimal solutions in high-dimensional spaces with limited data. | DANTE: Uses deep neural surrogate and tree search for efficient optimization [19]. |
| Differentiable Scoring Functions | Guides AI generation by quantifying properties like binding affinity and synthetic accessibility. | Used in IDOLpro to steer diffusion models during molecule generation [41]. |
| Multi-Omics Data Platforms | Provides transcriptomic, proteomic, and metabolomic data for training AI models. | Integrates with AI to link chemical composition to pharmacodynamic mechanisms [37]. |
| In-vitro Validation Assays | Experimental confirmation of AI-predicted molecule properties and functions. | Surface Plasmon Resonance (SPR): Measures binding affinity and kinetics. Cell-based viability assays: Tests efficacy against bacterial strains [39]. |
| Organ-on-a-Chip (OoC) | Microphysiological system for simulating human organ function, enhanced by AI. | AI-enhanced OoC provides a human-relevant model for evaluating strain outputs, reducing animal testing [36]. |
| Digital Twins (DTs) | A virtual replica of a biological system or process for simulation and prediction. | AI-powered DTs of strains or organs simulate individual responses to perturbations [36]. |
| AN3199 | AN3199, MF:C17H18BNO5, MW:327.1 g/mol | Chemical Reagent |
| ACP-5862 | ACP-5862, CAS:2230757-47-6, MF:C26H23N7O3, MW:481.5 g/mol | Chemical Reagent |
Diagram: Signaling Pathway for AI-Driven Q-Marker Discovery
The experimental data and comparative analysis presented in this guide compellingly demonstrate that generative AI and molecular modeling are not merely incremental improvements but foundational technologies redefining the possibilities in novel strain design. The ability of AI to explore vast biological spaces, solve high-dimensional optimization problems, and seamlessly integrate multi-objective constraints results in solutions that are structurally distinct, functionally superior, and discovered in a fraction of the time required by traditional methods [39] [19] [41]. The validation of these approaches through rigorous wet-lab experiments and their successful application against challenging, therapeutically relevant targets underscores their readiness for mainstream adoption.
The future of strain optimization lies in the continued refinement of these AI-driven workflows. This includes the development of more generalizable models, improved integration of multi-scale biological data, and the establishment of robust regulatory frameworks for AI-designed biologics [42]. As these tools become more accessible and their predictive power进一æ¥å¢žå¼º, they will undoubtedly accelerate the delivery of next-generation biotherapeutics, sustainable biomaterials, and innovative solutions to global health challenges.
Virtual Screening and In-Silico Prediction of Strain Performance
The validation of artificial intelligence (AI)-driven approaches against traditional methods is a pivotal area of modern scientific research, particularly in the field of strain analysis and drug discovery. Traditional virtual screening methods, such as molecular docking, rely on physics-based scoring functions to predict how a small molecule (ligand) interacts with a biological target. While useful, these methods can struggle with accuracy and efficiency, especially when dealing with resistant strains caused by mutations. AI-driven methods, particularly machine learning (ML) scoring functions, are revolutionizing this field by learning from vast datasets of known interactions to make more accurate and nuanced predictions. This guide provides a comparative analysis of leading virtual screening tools and methodologies, focusing on their performance in predicting activity against specific biological strains, to inform researchers and drug development professionals.
Performance Comparison of Screening Methods
The performance of virtual screening tools is typically benchmarked using metrics that measure their ability to distinguish known active molecules from inactive decoys. Key performance indicators include the Area Under the Curve (AUC) of the receiver operating characteristic curve and the Enrichment Factor (EF), which quantifies the method's ability to rank active molecules highly within a large library of compounds. The following data, derived from a benchmarking study on Plasmodium falciparum Dihydrofolate Reductase (PfDHFR) wild-type (WT) and quadruple-mutant (Q) strains, illustrates the comparative performance of various docking and re-scoring strategies [43].
Table 1: Performance Comparison of Docking Tools and ML Re-scoring for Wild-Type (WT) PfDHFR
| Docking Tool | Re-scoring Method | Primary Performance Metric (EF 1%) | Key Strength |
|---|---|---|---|
| AutoDock Vina | None (Classical Scoring) | Worse-than-random | Common, widely-used tool [43] |
| AutoDock Vina | RF-Score-VS v2 | Better-than-random | ML re-scoring significantly improves performance [43] |
| AutoDock Vina | CNN-Score | Better-than-random | ML re-scoring significantly improves performance [43] |
| PLANTS | None (Classical Scoring) | Not specified (Baseline) | - |
| PLANTS | CNN-Score | 28 | Best overall enrichment for WT variant [43] |
Table 2: Performance Comparison of Docking Tools and ML Re-scoring for Quadruple-Mutant (Q) PfDHFR
| Docking Tool | Re-scoring Method | Primary Performance Metric (EF 1%) | Key Strength |
|---|---|---|---|
| FRED | None (Classical Scoring) | Not specified (Baseline) | - |
| FRED | CNN-Score | 31 | Best overall enrichment for resistant Q variant [43] |
The data demonstrates that the combination of classical docking tools with modern ML re-scoring consistently outperforms traditional docking alone. Notably, the optimal docking tool can vary depending on the specific strain (e.g., wild-type vs. mutant), underscoring the importance of method selection in strain-specific optimization. The CNN-Score ML function provided a substantial performance boost across multiple docking tools, achieving the highest recorded enrichment factors for both the WT and Q strains [43].
Experimental Protocols for Benchmarking
To ensure the reproducibility of virtual screening benchmarks, a detailed and standardized experimental protocol is essential. The following methodology is adapted from a rigorous benchmarking analysis [43].
Protein Structure Preparation
- Source: Crystal structures for the target proteins (e.g., PDB ID: 6A2M for WT PfDHFR and PDB ID: 6KP2 for the quadruple-mutant) are downloaded from the Protein Data Bank [43].
- Software & Processing: Protein preparation is conducted using tools like OpenEye's "Make Receptor" GUI. The process involves:
- Removing water molecules, unnecessary ions, and redundant chains.
- Adding and optimizing hydrogen atoms.
- Saving the final prepared structure in the required format for subsequent docking steps (e.g., OEDU or PDB) [43].
Ligand and Decoy Set Preparation
- Benchmark Set: The DEKOIS 2.0 protocol is employed to create a benchmark set. This involves curating a set of known bioactive molecules (e.g., 40 actives) and generating a larger set of challenging, structurally similar but presumed inactive molecules (decoys) at a typical ratio of 1:30 actives to decoys [43].
- Ligand Preparation: All small molecule structures are prepared using software like Omega to generate multiple conformations. File formats are converted as needed for different docking programs (e.g., SDF to PDBQT for AutoDock Vina using OpenBabel, or SDF to mol2 for PLANTS using SPORES) [43].
Docking and Re-scoring Experiments
- Docking Tools: Multiple docking programs are run for comparison (e.g., AutoDock Vina, PLANTS, FRED). The docking grid box is defined to encompass the entire binding site of the prepared protein structure [43].
- Machine Learning Re-scoring: The top poses generated by each docking tool are subsequently re-scored using pretrained ML scoring functions such as RF-Score-VS v2 (based on a random forest algorithm) and CNN-Score (based on a convolutional neural network). These ML models have been shown to achieve hit rates more than three times higher than classical scoring functions at the top 1% of ranked molecules [43].
Performance Evaluation
- Metrics: The screening performance is evaluated by analyzing the enrichment behavior using metrics like the logAUC of the ROC curve (pROC-AUC) and the Enrichment Factor at 1% (EF 1%). pROC-Chemotype plots can be used to assess the diversity of the retrieved active molecules [43].
Workflow and Pathway Visualizations
Virtual Screening Benchmarking Workflow
AI vs. Traditional Screening Pathways
The Scientist's Toolkit: Key Research Reagents and Software
A successful virtual screening campaign relies on a suite of specialized software tools and databases. The following table details essential "research reagents" for in-silico prediction of strain performance.
Table 3: Essential Research Reagents for Virtual Screening
| Tool / Database Name | Type | Primary Function in Workflow |
|---|---|---|
| Protein Data Bank (PDB) | Database | Repository for 3D structural data of proteins and nucleic acids; source of initial target structure [43]. |
| DEKOIS 2.0 | Database | Provides benchmark sets with known active molecules and carefully selected decoys to evaluate screening performance [43]. |
| OpenEye Toolkits | Software | Suite used for protein preparation (Make Receptor), ligand conformation generation (Omega), and docking (FRED) [43]. |
| AutoDock Vina | Software | Widely-used molecular docking program that predicts ligand binding modes and scores them with a classical scoring function [43]. |
| PLANTS | Software | Molecular docking software that employs an ant colony optimization algorithm to search for ligand binding poses [43]. |
| CNN-Score | Software | A pretrained machine learning scoring function based on a convolutional neural network that significantly improves enrichment when used for re-scoring docking poses [43]. |
| RF-Score-VS v2 | Software | A pretrained machine learning scoring function based on a random forest algorithm designed to improve virtual screening hit rates [43]. |
| ChEMBL | Database | A large, open-access database of bioactive molecules with drug-like properties, containing curated binding data and target information [44]. |
| (1R,3S-)Solifenacin-d5hydrochloride | (1R,3S-)Solifenacin-d5hydrochloride, MF:C23H27ClN2O2, MW:404.0 g/mol | Chemical Reagent |
| Antitumor agent-183 | Antitumor agent-183, MF:C31H33BrN4O9, MW:700.6 g/mol | Chemical Reagent |
The iterative process of the Design-Build-Test-Learn (DBTL) cycle is fundamental to microbial strain development for sustainable chemical and fuel production. While synthetic biology tools have streamlined the "Build" phase, the "Test" phase, involving phenotype-based strain screening, remains a major bottleneck, traditionally relying on low-throughput, macroscopic colony plate assays [45] [46]. The integration of Artificial Intelligence (AI) with advanced robotics is fundamentally reshaping this cycle, creating a closed-loop system where AI's predictions are physically validated and refined through automated experimentation. This comparison guide objectively examines the performance of emerging AI-driven robotic platforms against traditional manual methods, providing researchers and drug development professionals with the data and methodologies needed to navigate this technological shift.
Performance Comparison: AI-Driven Robotics vs. Traditional Methods
The transition from manual workflows to integrated AI-robotics systems yields measurable improvements in speed, throughput, and outcomes. The table below provides a quantitative comparison.
Table 1: Quantitative Comparison of Strain Optimization Methods
| Feature | Traditional Manual Methods | AI-Driven Robotic Platforms |
|---|---|---|
| Experimental Throughput | Dozens to hundreds of formulations per cycle [47] | 3,000+ formulations screened in 4 weeks; 34x increase in throughput [47] |
| Typical Optimization Cycle | Several weeks per cycle [47] | Months of iteration compressed into weeks [47] [46] |
| Key Performance Outcome | Baseline for yield and cost improvement | 34.1% increase in biomass yield; 27.6% reduction in media cost [47] |
| Measurement Resolution | Population-level, bulk measurements [45] | Single-cell resolution with dynamic monitoring [45] |
| Data & Analytical Output | Manual data entry; limited, subjective analysis | AI-powered image recognition; multi-modal phenotyping (growth, morphology, metabolism) [45] |
| Financial Impact | High manual labor cost; slower ROI | 283% ROI after 10 batches; investment breaks even within first three production batches [47] |
Experimental Protocols: From Colony Picking to Reinforcement Learning
Protocol 1: AI-Powered Digital Colony Picking for Single-Cell Screening
This protocol uses an AI-powered Digital Colony Picker (DCP) for high-throughput, contact-free screening based on single-cell phenotypes [45].
- 1. System Setup: The core hardware includes a microfluidic chip with 16,000 picoliter-scale microchambers, an optical microscopy and laser module, a precision motion platform, and a droplet export module.
- 2. Single-Cell Loading and Cultivation:
- Prepare a single-cell suspension at an optimized concentration (e.g., 1×10ⶠcells/mL for 300 pL chambers) to maximize single-cell occupancy based on Poisson distribution [45].
- Load the suspension into the microfluidic chip using vacuum assistance, filling the microchambers in under a minute.
- Incubate the chip under high-precision temperature control. Gas-phase isolation between chambers prevents cross-contamination and allows for dynamic media replacement via the chip inlet.
- 3. AI-Powered Identification and Sorting:
- After incubation, inject an oil phase into the chip to prepare for droplet collection.
- The system automatically images each microchamber. An AI-driven image recognition model analyzes the images in real-time to identify microchambers containing monoclonal colonies based on target phenotypic signatures (e.g., growth rate, morphology).
- For each target clone, the motion platform positions a laser focus at the base of its microchamber. The Laser-Induced Bubble (LIB) technique generates a microbubble, propelling the single-clone droplet toward the outlet for contact-free collection into a 96-well plate.
- 4. Validation: Validate the performance of selected strains in larger bioreactors (e.g., 4L) under production-like conditions [47].
Protocol 2: Multi-Agent Reinforcement Learning for Strain Optimization
This protocol outlines a model-free Multi-Agent Reinforcement Learning (MARL) approach to optimize metabolic enzyme levels for improved production [46].
- 1. Problem Formulation:
- Actions: Define a vector of changes to the expression levels of a set of metabolic enzymes.
- States: Define a vector of observable variables, such as metabolite concentrations and enzyme expression levels, assessed during a pseudo steady-state (e.g., exponential growth phase).
- Rewards: Define the target for improvement, typically the change in a key performance indicator (e.g., product yield or the product of specific production and growth rates) between two consecutive experimental rounds.
- 2. Initial Round of Cultivation:
- Generate an initial library of strains with combinatorial modifications.
- Cultivate these strains in parallel (e.g., using multi-well plates or parallel bioreactors) and measure the state variables and target yield to establish a baseline.
- 3. Learning and Recommendation Cycle:
- The MARL algorithm, using a history of state-action-reward triples, learns a policy that maps the observed states to promising actions. The Maximum Margin Regression (MMR) framework is one method used to learn this policy efficiently [46].
- Based on the learned policy, the algorithm recommends a new set of strains with specific modifications to the enzyme levels for the next round of experimentation.
- 4. Iteration: The DBTL cycle is repeated. New strains are built and cultivated based on the AI's recommendations, and the resulting data is used to refine the policy further, progressively guiding the strain design toward optimal performance.
Visualization of Workflows
AI-Robotics Integrated Workflow
Single-Cell Screening Process
The Scientist's Toolkit: Key Research Reagent Solutions
Table 2: Essential Materials for Automated Strain Optimization
| Item | Function in Experiment |
|---|---|
| Microfluidic Chips (e.g., DCP Chip) | Contains thousands of addressable microchambers for high-throughput single-cell isolation, cultivation, and contact-free export [45]. |
| Multi-Well Plates (e.g., 96-well and 384-well) | Standardized plates for parallel cultivation of strain libraries in screening assays and for collecting exported clones from automated systems [45] [46]. |
| Liquid Handling Reagents | Includes buffers, culture media, and chemical inducters prepared for automated pipetting and dispensing by robotic systems [12]. |
| AI and Analysis Software | Software platforms (e.g., Cenevo, Sonrai Analytics) that integrate robotic data generation with AI-guided optimization, managing experimental data and generating insights [12]. |
| Specialized Culture Media | Formulations optimized for specific microbial chassis (e.g., Zymomonas mobilis, E. coli); AI is used to find simpler, cheaper, and higher-yielding recipes [47] [45]. |
| Biosensors & Reporter Assays | Tools integrated into the workflow to report on real-time metabolic activity or stress levels, providing the phenotypic data for AI analysis [45]. |
| sEH inhibitor-12 | sEH inhibitor-12, MF:C21H22ClN3O2S, MW:415.9 g/mol |
Navigating the Hype: Troubleshooting AI Models for Real-World Reliability
In the competitive landscape of industrial biotechnology, the race to develop high-yielding microbial strains is increasingly a race for high-quality data. Artificial Intelligence (AI) and machine learning (ML) promise to revolutionize strain optimization, compressing development timelines that traditionally relied on labor-intensive, trial-and-error approaches [9] [48]. However, the performance of these AI models is critically dependent on the data used to train them. The principle of "garbage in, garbage out" is particularly salient; without reliable data, even the most sophisticated AI can produce flawed outcomes [49]. This guide objectively compares the performance of AI-driven and traditional strain validation methods, framing the analysis within the imperative of addressing the AI-ready data gap through robust quality management, sufficient data volume, and rigorous standardization.
Comparative Analysis: AI-Driven vs. Traditional Strain Validation
The transition from traditional methods to AI-driven discovery represents a paradigm shift, replacing human-driven workflows with AI-powered engines capable of compressing timelines and expanding biological search spaces [9]. The table below summarizes a quantitative comparison of the two approaches.
Table 1: Performance Comparison of Traditional vs. AI-Driven Strain Validation Methods
| Performance Metric | Traditional Methods | AI-Driven Methods | Supporting Experimental Data |
|---|---|---|---|
| Early-Stage Research Timeline | ~5 years for discovery and preclinical work [9] | As little as 18 months from target discovery to Phase I trials [9] | Insilico Medicine's idiopathic pulmonary fibrosis drug candidate [9] |
| Lead Optimization Efficiency | Industry standard compound synthesis and testing [9] | ~70% faster design cycles; 10x fewer synthesized compounds [9] | Exscientia's automated precision chemistry platform [9] |
| Cost Implications | High cost associated with lengthy timelines and high compound failure rates [48] | Up to 45% reduction in development costs [48] | Industry projections based on AI integration [48] |
| Data Processing Capability | Limited by human capacity for data analysis; reliance on historical modeling [50] | Analysis of massive genomic, proteomic, and metabolomic datasets at lightning speed [48] | Use of large-scale biological data for target identification and compound prediction [48] |
| Success Rate in Clinical Stages | Most programs remain in early-stage trials [9] | Dozens of AI-designed candidates in clinical trials by mid-2025 [9] | Over 75 AI-derived molecules in clinical stages by end of 2024 [9] |
Analysis of Comparative Data
The data in Table 1 indicates a significant acceleration in early-stage research and lead optimization through AI. For instance, companies like Exscientia have demonstrated that AI-driven design can substantially reduce the number of compounds that need to be synthesized and tested, a process critical to strain optimization [9]. This efficiency stems from AI's ability to predict molecular behavior and optimize compounds in silico before any wet-lab experimentation [48]. Furthermore, the capability to process vast and complex biological datasets—including genomics, proteomics, and metabolomics—allows AI to identify patterns and promising strain engineering targets that would be impractical for human researchers to uncover manually [48] [50]. While the clinical success of AI-designed therapeutics is still being established, the surge of candidates into trials signals growing confidence in the approach [9].
The Pillars of AI-Ready Data in Strain Optimization
The superior performance of AI models is contingent upon the quality of their input data. For strain optimization, this data encompasses genomic sequences, phenotypic screening results, transcriptomic data, and metabolomic profiles. Bridging the AI-ready data gap requires a focused strategy on three core pillars.
Data Quality and Cleansing
Data quality refers to the condition of data across dimensions such as accuracy, completeness, conformity, and consistency [51]. Flawed data can lead to incorrect model predictions, wasted resources, and failed experiments. A structured approach to data quality is essential.
- Data Profiling and Discovery: This is the foundational step of examining existing datasets to create a comprehensive summary of their characteristics. It involves statistical analyses to reveal the true nature of the data's structure, content, and relationships, uncovering patterns, identifying outliers, and measuring adherence to standards [52]. This transforms data quality from a reactive exercise into a proactive discipline.
- Data Cleansing and Standardization: This process involves correcting errors in existing data, including rectifying inaccuracies, removing duplicate records, and filling in missing values [53]. Standardization transforms data into a consistent, common format (e.g., ensuring all gene identifiers use the same nomenclature), which is crucial for making data comparable and ready for analysis [53] [51].
- Automated Data Validation: The most effective way to ensure quality is to prevent bad data at the point of entry. Implementing validation rules in data collection systems can verify data formats, ensure completeness, and check for validity against predefined acceptable values [53] [52].
Data Volume and Volume Management
AI and ML models, particularly deep learning models, require large volumes of diverse data to learn effectively and avoid overfitting. In strain optimization, this means generating high-throughput phenomic and genomic data.
- High-Throughput Phenomic Screening: Companies like Recursion leverage automated, high-throughput cell biology to generate massive, reproducible datasets on how genetic perturbations affect cell morphology [9]. This creates a rich training ground for AI models to identify novel biological interactions.
- Federated Learning for Data Collaboration: The pharmaceutical industry is moving towards collaborative ecosystems where organizations can pool data resources without sharing sensitive raw data. Federated learning allows AI models to learn from data across multiple institutions without the data ever leaving its secure home base, thus overcoming data volume limitations while preserving privacy and intellectual property [48].
Data Standardization and Governance
Standardization ensures that data from different experiments, batches, or even organizations can be integrated and compared. This is enabled by a strong data governance framework.
- Data Governance Framework: Data governance is the cornerstone of data quality management [53]. It defines the policies, standards, and procedures for how data is collected, stored, used, and protected. An effective framework clarifies ownership and accountability, typically involving a data governance council and appointed data stewards who are responsible for data within specific domains [53] [49].
- Master Data Management (MDM): For critical reference data in strain optimization—such as standard strain names, gene identifiers, or chemical compounds—Master Data Management (MDM) is crucial. MDM creates an authoritative "single source of truth" for this core data, eliminating the costly confusion that arises when different systems or teams hold conflicting versions of the same information [53] [52].
- Data Lineage Tracking: Data lineage provides clarity on data changes from its origin to its final insights. It offers a thorough overview of how data progresses through various stages, which is invaluable for troubleshooting, understanding the impact of changes, and meeting regulatory compliance requirements [51].
Table 2: Essential Research Reagent Solutions for AI-Ready Data Generation
| Reagent / Solution | Function in Experimental Protocol |
|---|---|
| High-Throughput Sequencing Kits | Generate the foundational genomic data (e.g., whole genome sequencing of engineered strains) required for training AI models on genotype-phenotype relationships. |
| Cell Staining and Labeling Reagents | Enable high-content phenotypic screening by marking cellular components (e.g., nuclei, membranes) for automated imaging and analysis, creating quantitative morphological data. |
| Metabolomics Assay Kits | Quantify metabolite concentrations from cultured strains, providing critical data on metabolic flux and end-product yields for optimizing production pathways. |
| Standardized Growth Media | Ensure experimental consistency and reproducibility across different batches and labs, a key requirement for generating comparable and reliable data for AI training. |
| Proteomic Analysis Kits | Facilitate the identification and quantification of protein expression in engineered strains, adding a crucial layer of functional data to genomic information. |
Experimental Protocols for Data Generation and Model Validation
The credibility of AI-driven strain optimization hinges on rigorous, reproducible experimental protocols for both generating training data and validating model predictions.
Protocol for High-Throughput Phenomic Screening for AI Training
This protocol is adapted from the phenomics-first systems used by leading AI companies to generate rich, quantitative biological data [9].
- Strain Cultivation and Plate Preparation: Aliquot engineered strains and control strains into 384-well microplates using liquid handling robots. Grow cultures under standardized conditions to a defined optical density.
- Perturbation and Staining: Treat cultures with a library of chemical or genetic perturbations. Fix cells and stain with fluorescent dyes targeting specific cellular structures (e.g., DNA, actin, membranes).
- Automated High-Content Imaging: Image each well of the microplates using a high-content microscope with automated stage control. Capture multiple fields of view per well across several fluorescence channels.
- Feature Extraction and Data Processing: Use image analysis software to extract quantitative morphological features (e.g., cell size, shape, intensity, texture) for each cell in every image. This process can generate thousands of features per cell, creating a massive, multidimensional dataset.
- Data Aggregation and Labeling: Aggregate cell-level features into well-level profiles. Label each profile with the associated strain genotype and perturbation. This curated, standardized dataset is then used to train AI models to predict phenotypic outcomes from genetic inputs.
Protocol for Validating AI-Generated Strain Hypotheses
When an AI model proposes a promising genetic modification for improved yield, this protocol validates its prediction.
- In Silico Design and Prioritization: The AI platform outputs a ranked list of proposed genetic edits (e.g., gene knockouts, promoter swaps) with predicted performance scores.
- Strain Engineering: Using standard genetic engineering techniques (e.g., CRISPR-Cas9, homologous recombination), construct the top-predicted strain designs in the host microbial chassis.
- Controlled Bioreactor Cultivation: Inoculate the AI-designed strains and appropriate control strains (e.g., wild-type, a traditionally optimized strain) into parallel, controlled bioreactors. This ensures consistent and comparable environmental conditions.
- Performance Phenotyping: Monitor growth metrics (e.g., OD600) and periodically sample the culture to measure the titer, yield, and productivity of the target molecule. Compare the performance of the AI-predicted strains against the controls.
- Data Feedback for Model Refinement: The results from the physical experiment are fed back into the AI model's dataset. This "closed-loop" learning allows the model to continuously improve its prediction accuracy over successive design-test-learn cycles [9].
Visualizing the AI-Driven Strain Optimization Workflow
The following diagram illustrates the integrated, closed-loop workflow of an AI-driven strain optimization platform, highlighting the critical role of high-quality data at each stage.
AI-Driven Strain Optimization Workflow
The competitive advantage in modern biomanufacturing will be determined by the ability to not only generate data but to manage it as a strategic asset. As this guide has detailed, AI-driven methods offer a compelling performance advantage over traditional strain validation in terms of speed, efficiency, and exploratory power [9] [48]. However, this advantage is entirely dependent on the foundation of AI-ready data—characterized by impeccable quality, sufficient volume, and rigorous standardization. Investing in the strategic framework of data governance, automated quality tools, and collaborative data ecosystems is not merely an IT initiative; it is a fundamental prerequisite for unlocking the full potential of AI and driving a new era of innovation in strain optimization and drug development.
Combating Algorithmic Bias and Ensuring Model Fairness
In the context of AI-driven strain optimization and traditional methods validation, algorithmic bias is not merely a technical nuisance but a fundamental issue that can compromise scientific integrity and lead to erroneous conclusions. Artificial intelligence bias, or AI bias, refers to systematic discrimination embedded within AI systems that can reinforce existing biases and amplify discrimination, prejudice, and stereotyping [54]. For researchers, scientists, and drug development professionals, the stakes are particularly high—biased models can skew experimental results, misdirect research resources, and ultimately hinder scientific progress.
The integration of AI into preclinical research and drug discovery represents a paradigm shift, offering innovative alternatives to traditional methods like animal testing through techniques including machine learning (ML), deep learning (DL), AI-powered digital twins (DTs), and AI-enhanced organ-on-a-chip (OoC) platforms [36]. However, these technologies' predictive power and scalability depend entirely on the fairness and robustness of their underlying algorithms. A biased model in strain optimization could, for instance, systematically underperform with certain biological strains due to inadequate representation in training data, leading to inaccurate efficacy predictions and failed experiments. Understanding and mitigating these biases is therefore essential for establishing AI as a cornerstone of ethical and efficient scientific discovery.
Algorithmic bias in scientific AI applications typically originates from multiple sources that can affect the fairness and reliability of research outcomes. Understanding these sources is the first step toward effective mitigation.
- Data Bias: This occurs when the data used to train AI models is unrepresentative or flawed [54] [55]. In scientific contexts, this could manifest as a biomedical image dataset lacking diversity in genetic backgrounds, demographic factors, or disease subtypes, leading to models that perform poorly on underrepresented populations [56].
- Algorithmic Bias: This form of bias arises from the design and implementation of the algorithms themselves [54] [57]. Even with unbiased data, the way algorithms process information and prioritize certain features can introduce discriminatory patterns, potentially overlooking critical but subtle biological signals in strain optimization tasks.
- Human Bias: Also known as cognitive bias, this can seep into AI systems through the subjective decisions made by researchers and developers during data labeling, feature selection, and model development [54] [55]. These biases reflect the unconscious assumptions and limited perspectives of the individuals involved in the AI lifecycle.
The table below summarizes common types of bias and their potential impact on scientific research.
Table 1: Common Types of Bias in Scientific AI Applications
| Bias Type | Description | Potential Research Impact |
|---|---|---|
| Historical Bias [57] | Preexisting societal biases present in the training data. | Replicating and amplifying past scientific inaccuracies or inequalities in resource allocation. |
| Representation Bias [58] [57] | Underrepresentation of certain groups or conditions in the dataset. | Reduced model accuracy for rare strains, minority demographics, or uncommon disease variants. |
| Measurement Bias [58] [57] | Systematic errors in data collection instruments or procedures. | Flawed experimental data leading to incorrect conclusions about strain behavior or drug efficacy. |
| Evaluation Bias [57] | Use of inappropriate or non-representative benchmarks for model validation. | Overestimation of model performance, creating false confidence in its predictions for real-world applications. |
| Algorithmic Bias [54] [57] | Bias introduced by the model's design and optimization objectives. | Models that prioritize certain biological features over others, potentially missing key mechanistic insights. |
A Framework for Mitigating Bias in Research AI Systems
Effectively addressing bias requires a comprehensive, multi-stage approach that spans the entire AI development lifecycle. The following workflow outlines a structured methodology for integrating bias mitigation into scientific AI projects.
Diagram 1: AI Bias Mitigation Workflow for Scientific Research
Data Pre-Processing and Auditing
The first line of defense against bias involves rigorous scrutiny and preparation of the training data. This includes:
- Data Audits: Collaborating with data teams to implement rigorous audits ensuring datasets are representative and free from bias [54]. This involves regular reviews of the training data to identify potential issues related to demographic, genetic, or experimental condition representation.
- Pre-Processing Techniques: Applying techniques to clean, transform, and balance data to reduce the influence of discrimination before model training [54]. This may involve re-sampling underrepresented classes or generating synthetic data to address data scarcity and balance representation [54] [56].
Fairness-Aware Model Development
During the model development phase, specific strategies can be employed to encode fairness directly into the algorithms.
- Fairness-Aware Algorithms: This approach involves coding rules and guidelines to ensure that the outcomes generated by AI models are equitable across all individuals or groups involved [54]. Techniques include adversarial de-biasing and incorporating fairness constraints into the model's objective function.
- Explainable AI (XAI): There is a growing demand for transparency in AI decision-making processes [54]. XAI aims to make the workings of AI systems understandable to researchers, helping them grasp how decisions are made and ensuring accountability, which is critical for validating models against traditional methods.
Post-Processing and Continuous Monitoring
Bias mitigation continues after the model is deployed.
- Post-Processing Techniques: This involves adjusting the outcomes of AI models after a decision is made to ensure fair treatment [54]. For instance, a model's output scores for different strain types could be calibrated to ensure equitable performance across categories.
- Continuous Monitoring and Auditing: Organizations should implement governance frameworks that define accountability and oversight for AI systems [54] [55]. This includes regular monitoring in production to detect emerging biases from data drift and to assess compliance with established ethical standards.
Experimental Protocols for Benchmarking Model Fairness
To objectively compare the fairness of different AI models, standardized evaluation protocols are essential. The following section provides a detailed methodology for conducting a robust fairness audit, suitable for use in a research environment.
Protocol: Multi-Dimensional Fairness Assessment
Objective: To quantitatively evaluate and compare the performance and fairness of multiple AI models across diverse demographic groups and experimental conditions.
Materials:
- Evaluation Datasets: The Fair Human-Centric Image Benchmark (FHIBE) is a publicly available, consensually collected dataset featuring comprehensive annotations for demographic and physical attributes, enabling granular bias diagnoses [56]. For specific domains, licensed or proprietary datasets that include self-reported demographic information may be used.
- Models for Comparison: A selection of AI models to be evaluated (e.g., various pre-trained models for image analysis, or custom models for strain classification).
- Computing Environment: Adequate computational resources (GPU recommended) for running model inferences.
- Evaluation Framework: Software tools for calculating fairness metrics (e.g., IBM AI Fairness 360, Microsoft Fairlearn).
Procedure:
- Data Preparation: Partition the evaluation dataset into subgroups based on relevant sensitive attributes (e.g., ancestry, Fitzpatrick skin tone, age group, biological strain characteristics) as defined by the dataset's annotations [56].
- Model Inference: Run each model under evaluation on the entire dataset and its predefined subgroups, recording outputs (e.g., classification labels, prediction scores, bounding boxes).
- Performance Calculation: For each model and each subgroup, calculate standard performance metrics (e.g., Accuracy, Precision, Recall, F1-score, mAP).
- Fairness Metric Computation: Calculate a suite of fairness metrics to quantify disparities in model performance across subgroups. Key metrics include:
- Demographic Parity: Assesses whether predictions are independent of the sensitive attribute.
- Equalized Odds: Evaluates if the model has equal true positive and false positive rates across groups.
- Predictive Rate Parity: Checks if the precision is similar across different groups.
- Bias Diagnosis: Analyze the results to identify performance gaps and correlate them with specific attributes or environmental factors captured in the dataset annotations [56].
- Statistical Analysis: Perform significance testing to determine if observed performance disparities are statistically significant.
Key Reagents and Research Solutions
The table below lists essential tools and datasets required for implementing the described fairness evaluation protocol.
Table 2: Research Reagent Solutions for AI Fairness Evaluation
| Item Name | Function/Brief Explanation | Example/Source |
|---|---|---|
| FHIBE Dataset | A consent-based, globally diverse image dataset for fairness evaluation across multiple computer vision tasks. Provides granular annotations for bias diagnosis. | Publicly available dataset described in Nature (2025) [56]. |
| Bias Evaluation Framework | Open-source software toolkits that provide a standardized set of metrics and algorithms for auditing and mitigating bias in ML models. | IBM AI Fairness 360 (AIF360); Microsoft Fairlearn [59]. |
| Model Benchmarking Platform | Platforms that provide comprehensive evaluation frameworks, including operational and ethical benchmarks for AI models. | Azure AI Foundry [59]. |
| Synthetic Data Generators | Tools to generate synthetic data to augment training sets, addressing data scarcity and bias without compromising privacy. | Generative Adversarial Networks (GANs), such as Tox-GAN for drug discovery [54] [36]. |
Comparative Analysis of AI Fairness Performance
Applying the experimental protocol above allows for a data-driven comparison of AI models. The following tables summarize hypothetical but representative results from a fairness benchmark study, illustrating how different models might perform.
Table 3: Comparative Performance Metrics Across Ancestry Groups (Face Verification Task)
| Model | Overall Accuracy | Subgroup A Accuracy | Subgroup B Accuracy | Subgroup C Accuracy | Max Performance Gap |
|---|---|---|---|---|---|
| Model Alpha | 98.5% | 99.1% | 98.9% | 95.2% | 3.9% |
| Model Beta | 97.8% | 98.5% | 97.5% | 97.0% | 1.5% |
| Model Gamma | 99.0% | 99.2% | 99.1% | 98.5% | 0.7% |
Table 4: Fairness Metrics Comparison (Equalized Odds Difference - Lower is Better)
| Model | Gender (Male/Female) | Skin Tone (Light/Dark) | Age (Young/Old) | Composite Fairness Score |
|---|---|---|---|---|
| Model Alpha | 0.03 | 0.12 | 0.08 | 0.077 |
| Model Beta | 0.02 | 0.04 | 0.05 | 0.037 |
| Model Gamma | 0.01 | 0.02 | 0.03 | 0.020 |
Table 5: Operational Benchmarks for Deployed Models
| Model | Inference Latency (ms) | Cost per 1k Inferences ($) | Robustness Score | Explainability Support |
|---|---|---|---|---|
| Model Alpha | 120 | 0.45 | 85/100 | Limited |
| Model Beta | 95 | 0.52 | 92/100 | Full (XAI) |
| Model Gamma | 150 | 0.38 | 88/100 | Partial |
Interpretation of Results: The comparative data reveals critical trade-offs. While Model Alpha may achieve high overall accuracy, its significant performance gap across ancestry subgroups (3.9%) and poor skin tone fairness metric (0.12) indicate a high risk of discriminatory outcomes, making it unsuitable for equitable research applications. Model Beta shows a more balanced profile, with minimal performance gaps and strong fairness metrics, though at a slightly higher operational cost. Model Gamma emerges as the most balanced candidate, demonstrating top-tier fairness (Composite Score of 0.02) with minimal performance disparity, robust accuracy, and explainability support, justifying its potential selection for sensitive research tasks where fairness is paramount. This analysis underscores that overall accuracy is an insufficient metric on its own; a multi-dimensional evaluation encompassing fairness and operational factors is essential for selecting models for scientific use.
Combating algorithmic bias is not a one-time fix but an ongoing discipline that must be deeply integrated into the culture of scientific research. As AI becomes more entrenched in strain optimization and drug discovery, ensuring model fairness is synonymous with ensuring scientific validity and ethical responsibility. The frameworks, protocols, and comparative analyses presented provide a roadmap for researchers to systematically address bias.
The future of fair AI in science hinges on collaborative, interdisciplinary efforts. This includes fostering diversity among development teams to recognize blind spots [54], engaging with legal and compliance experts to establish robust governance [54], and supporting the development of more sophisticated consent-based benchmarking datasets like FHIBE [56]. By adopting a proactive "fairness-by-design" approach [54] and committing to continuous monitoring and transparency, the research community can harness the full power of AI-driven methods while upholding the highest standards of scientific rigor and equity.
The integration of Artificial Intelligence (AI) into life sciences represents a paradigm shift in research methodology. In fields such as drug development and cannabis strain optimization, AI promises unprecedented acceleration, from target identification and patient matching to predictive analysis of complex biochemical profiles [8] [60]. However, a significant barrier to the widespread adoption and regulatory acceptance of these technologies is the "black box" problem—the inherent difficulty in understanding how complex AI models, particularly deep learning networks, arrive at their predictions [42]. This opacity is unacceptable in a regulated research environment where decisions impact therapeutic outcomes and public health.
The move toward transparent, or "Explainable AI" (XAI), is no longer a theoretical pursuit but a clinical and regulatory imperative. Frameworks like the European Union's Artificial Intelligence Act (AI Act) and the U.S. Food and Drug Administration's (FDA) evolving guidance now mandate that high-risk AI systems used in healthcare must be transparent, explainable, and robust [42] [60]. For researchers and scientists, this means that an AI model's performance is no longer measured by accuracy alone; its reliability hinges on our ability to interrogate its decision-making process, validate its reasoning against domain knowledge, and establish trust in its outputs [42]. This guide objectively compares the performance of transparent AI approaches against traditional methods and less interpretable models, providing a framework for validation in rigorous scientific settings.
Comparative Analysis: Transparent AI vs. Black Box Models & Traditional Methods
The following tables provide a quantitative comparison of AI model types and their performance against traditional research methods in the context of strain optimization and drug development.
Table 1: Performance Comparison of AI Model Types in Biological Research Applications
| Performance Metric | Black Box AI (e.g., Deep Neural Networks) | Transparent AI (e.g., Tree-based, XAI-enhanced) | Comparative Context |
|---|---|---|---|
| Predictive Accuracy | High (e.g., >95% in image classification) | Moderate to High (e.g., 87-96% in patient matching [8]) | Accuracy is often comparable, but the key difference is verifiability. |
| Training Data Requirements | Very High (e.g., 100,000+ samples) | Moderate (can be effective with smaller, curated datasets [61]) | Transparent models can be more data-efficient, reducing resource burdens. |
| Computational Cost | High | Low to Moderate [61] | Techniques like pruning and quantization can reduce costs for both, but are more effective for simpler, transparent models [61]. |
| Inference Speed | Can be slow; requires optimization via quantization [61] | Typically fast | Optimization techniques like quantization can be applied to both, but inherently simpler transparent models are faster [61]. |
| Adherence to EU AI Act & FDA Guidelines | Low (high-risk, requires extensive validation [42]) | High (built-in explainability facilitates compliance [42]) | For high-risk applications, transparent AI is the only viable path to regulatory approval. |
Table 2: Transparent AI vs. Traditional Research Methods in Strain Optimization
| Research Activity | Traditional Method | AI-Driven Approach | Experimental Data & Outcome |
|---|---|---|---|
| Strain Classification | Subjective categorization (Indica/Sativa/Hybrid) based on morphology. | Terpene profile clustering using Principal Component Analysis (PCA) and K-Means [62]. | AI analysis of 2,400 strains revealed 6 distinct chemotypes [62]. A Chi-squared test showed a significant but imperfect correlation with traditional labels, demonstrating AI's objective precision. |
| Trait Prediction | Generational selective breeding and phenotypic observation (months to years). | Predictive models linking genetic markers to expression of traits (e.g., pest resistance, terpene production) [63]. | AI enables deliberate breeding for specific traits like water efficiency or unique flavors, drastically accelerating development cycles [63]. |
| Quality Control & Anomaly Detection | Manual inspection and standardized lab tests. | AI-powered computer vision for automated visual inspection and anomaly detection [42]. | AI systems detect subtle defects with greater speed and accuracy than human inspectors, reducing waste by up to 25% [42]. |
| Patient Stratification & Matching | Manual screening of electronic health records (EHRs). | Natural Language Processing (NLP) of unstructured EHRs and predictive analytics [8]. | AI reduces patient screening time by 42.6% while maintaining 87.3% accuracy in matching patients to trial criteria [8]. |
Experimental Protocols for Validating Transparent AI
For AI models to be trusted in a research environment, their claims must be validated through rigorous, reproducible experimental protocols. The following methodologies are critical for benchmarking AI performance against traditional scientific methods.
Protocol: Validating Terpene-Based Strain Classification
This protocol outlines how to reproduce and validate the AI-driven strain classification system that identifies chemotypes based on terpene profiles, as described in the Strain Data Project [62].
1. Objective: To classify cannabis strains into distinct, chemically meaningful categories using unsupervised machine learning on terpene chromatograph data and to validate this classification against traditional labels.
2. Materials & Data Acquisition:
- Samples: A minimum of 2,400 unique, high-THC cannabis samples to ensure statistical power [62].
- Lab Equipment: Gas Chromatography coupled with Mass Spectrometry and Flame Ionization Detection (GC-MS/FID) for precise terpene quantification [62].
- Data: Terpene concentration data for each sample, standardized and cleaned. The dataset should be refined to include only Type I (high-THC) strains for initial consistency.
3. Methodological Steps:
- Step 1 - Data Preprocessing: Clean the raw terpene data, handling missing values and normalizing concentrations. This ensures data quality and integrity for model training.
- Step 2 - Dimensionality Reduction: Perform Principal Component Analysis (PCA). This technique reduces the complexity of the multi-terpene dataset, creating new variables (Principal Components) that explain the maximum variance. A Scree Plot is used to visualize how much variance each PC explains; the first five PCs should account for ~90% of variance [62].
- Step 3 - Cluster Analysis: Apply the K-Means Clustering algorithm to the PCA results to group strains with similar terpene profiles.
- Step 4 - Determine Optimal Cluster Count: Use the Silhouette Method to identify the ideal number of clusters (k). The analysis should indicate that either 3 or 6 clusters provide the best fit, with 6 offering more granularity [62].
- Step 5 - Statistical Validation: Conduct a Chi-Squared Test of independence on 2,149 observations to compare the new terpene-based categories against traditional Sativa, Indica, and Hybrid labels. A strong rejection of the null hypothesis (p < 0.05) confirms a significant correlation, validating that the AI-derived categories capture meaningful biological distinctions [62].
Protocol: Prospective Clinical Validation of an AI Model
This protocol is essential for moving an AI tool from a research concept to a clinically validated asset, as demanded by regulators and the scientific community [60].
1. Objective: To prospectively evaluate the safety and clinical benefit of an AI system in a real-world decision-making workflow, such as patient matching for clinical trials.
2. Study Design: A Randomized Controlled Trial (RCT) is the gold standard. For example, clinical sites can be randomized to use either an AI-powered patient screening tool or traditional manual screening methods [60].
3. Methodological Steps:
- Step 1 - Define Primary Endpoints: Establish clear, clinically meaningful endpoints. Examples include:
- Percentage reduction in patient screening time.
- Accuracy in patient-trial matching, measured by the percentage of patients who successfully enroll and remain in the trial.
- Rate of serious adverse events in the AI-selected cohort.
- Step 2 - Model Integration & Deployment: Integrate the AI tool into the clinical workflow at the intervention sites. This includes ensuring interoperability with Electronic Health Record (EHR) systems and training clinical staff on its use.
- Step 3 - Prospective Data Collection: Run the trial and collect data in real-time according to the pre-specified endpoints. This assesses the model's performance on new, unseen data, preventing issues of data leakage or overfitting common in retrospective studies [60].
- Step 4 - Explainability Output: For every prediction (e.g., "Patient X is a match for Trial Y"), the AI system must log a confidence score and use feature attribution techniques like SHAP or LIME to highlight the key data points (e.g., specific diagnostic codes, lab values) that drove the decision [42]. This allows researchers to audit and clinically validate the AI's reasoning.
- Step 5 - Analysis: Compare the primary endpoints between the AI and control groups using statistical tests to determine if the improvements are statistically significant.
Visualization of Workflows
The following diagrams, generated with Graphviz, illustrate the core workflows for the experimental protocols described above, highlighting the role of transparent AI.
Terpene-Based Strain Classification Workflow
Prospective AI Clinical Validation Workflow
The Scientist's Toolkit: Essential Reagents & Solutions for AI Validation
Successfully implementing and validating transparent AI in a research environment requires both computational and traditional laboratory tools. The following table details key components of the modern scientist's toolkit.
Table 3: Essential Research Reagent Solutions for AI-Driven Strain R&D
| Toolkit Component | Function & Explanation | Example Use-Case |
|---|---|---|
| Gas Chromatography-Mass Spectrometry (GC-MS) | The gold-standard instrument for separating, identifying, and quantifying terpenes and other volatile compounds in a plant sample. Provides the high-fidelity chemical data required to train and validate AI models [62]. | Generating the precise terpene concentration data used as input for the PCA and K-Means clustering in the strain classification protocol [62]. |
| Explainable AI (XAI) Software Libraries (e.g., SHAP, LIME) | Post-hoc interpretation tools that explain the output of any machine learning model. SHAP (SHapley Additive exPlanations) calculates the contribution of each input feature to a final prediction [42]. | Highlighting which terpenes (e.g., myrcene vs. limonene) were most influential in an AI model's classification of a strain into a specific chemotype [42] [62]. |
| Vector Database (e.g., Pinecone) | A specialized database designed to store and efficiently search high-dimensional data representations (vectors). Essential for managing the complex data outputs of AI models [64]. | Enabling rapid semantic search and retrieval of similar strain profiles based on their terpene or genetic vector embeddings, accelerating breeding research [64]. |
| Tissue Culture Propagation Supplies | A sterile laboratory technique for producing genetically identical plant clones. This ensures genetic stability when replicating desirable phenotypes identified through AI-driven pheno-hunting [63]. | Preserving and scaling a high-value, AI-identified phenotype that exhibits a rare terpene profile or disease resistance for further commercial development [63]. |
The field of microbial strain optimization for drug development and chemical production is undergoing a fundamental transformation, moving from traditional, labor-intensive methods to artificial intelligence (AI)-driven approaches. This shift promises to accelerate the development of sustainable bioprocesses and life-saving therapeutics but also introduces complex ethical challenges concerning data privacy, user consent, and responsible innovation. Traditional strain optimization typically relies on iterative Design, Build, Test, Learn (DBTL) cycles that require extensive manual evaluation by domain experts, a process that is both time-consuming and costly [46]. In contrast, emerging AI methodologies, particularly reinforcement learning, can navigate biological complexity beyond established mechanistic knowledge, potentially achieving industrially attractive production levels faster and more reliably [46].
This comparison guide objectively analyzes the performance, methodologies, and ethical implications of AI-driven strain optimization against traditional validation research. As AI systems process vast amounts of sensitive biological and experimental data, ensuring robust data privacy protections and ethical oversight becomes paramount. Organizations must implement privacy-by-design principles and adhere to regulations such as GDPR and CCPA to maintain trust and safeguard fundamental rights while leveraging AI's transformative potential [65]. The following sections provide a detailed comparison of these approaches, supported by experimental data, protocol details, and ethical analysis tailored for research scientists and drug development professionals.
Performance Comparison: Quantitative Analysis
Direct comparative analysis reveals significant differences in efficiency, resource requirements, and output quality between AI-driven and traditional strain optimization methods. The table below summarizes key performance metrics gathered from recent studies and implementation data.
Table 1: Performance comparison between AI-driven and traditional strain optimization methods
| Performance Metric | AI-Driven Methods | Traditional Methods | Data Source/Context |
|---|---|---|---|
| Patient Screening Time | 42.6% reduction [8] | Baseline | AI Clinical Trials |
| Patient Matching Accuracy | 87.3% accuracy [8] | Not specified | AI Clinical Trials |
| Process Cost Reduction | Up to 50% reduction [8] | Baseline | AI-powered document automation |
| Medical Coding Efficiency | 69 hours saved per 1,000 terms coded [8] | Baseline | AI Clinical Trials |
| Medical Coding Accuracy | 96% accuracy [8] | Lower than AI | AI Clinical Trials |
| Data Cleaning Throughput | 6.03-fold increase [10] | Baseline | AI-assisted medical data cleaning |
| Data Cleaning Errors | 8.48% (6.44-fold decrease) [10] | 54.67% | AI-assisted medical data cleaning |
| False Positive Queries | 15.48-fold reduction [10] | Baseline | AI-assisted medical data cleaning |
| Database Lock Timeline | 33% acceleration (5-day reduction) [10] | Baseline | Phase III oncology trial analysis |
| Strain Optimization Approach | Model-free Multi-Agent Reinforcement Learning (MARL) [46] | Manual evaluation in DBTL cycle [46] | Microbial strain engineering for chemical production |
The performance advantages of AI-driven approaches extend beyond speed to encompass improved accuracy and significant cost reductions. In clinical data cleaning, AI-assistance not only increased throughput by over 6-fold but also dramatically reduced errors from 54.67% to 8.48% [10]. The economic impact is substantial, with one analysis of a Phase III oncology trial revealing potential savings of $5.1 million, largely driven by accelerated database lock timelines [10]. For strain optimization specifically, AI methods like Multi-Agent Reinforcement Learning (MARL) demonstrate the capability to optimize enzyme levels in microbial systems without prior mechanistic knowledge of metabolic networks, efficiently navigating complex biological systems that challenge traditional methods [46].
Experimental Protocols and Methodologies
AI-Driven Strain Optimization Protocol
The AI-driven approach to strain optimization employs a Multi-Agent Reinforcement Learning (MARL) framework, which is particularly suited for parallel experimentation such as multi-well plate cultivation systems [46]. This methodology operates through defined cycles that integrate computational prediction with experimental validation:
- Actions: Real-valued vectors specifying changes to metabolic enzyme levels (dimension n~a~). These represent genetic engineering modifications intended to increase or decrease expression of targeted enzymes [46].
- States: Vectors containing steady-state concentrations of metabolites and enzymes (dimension n~s~) measured during cultivation, typically during exponential growth phase [46].
- Rewards: The change in the target variable (e.g., product yield, specific production rate) between consecutive experimental rounds, calculated as r~t~ = y~t~ - y~t-1~ [46].
- Policy: The mapping from observed states to actions, learned from historical data and continuously refined. This is implemented using Maximum Margin Regression (MMR), which learns a linear operator W: H~S~ → H~A~ mapping state and action feature spaces to predict rewarding actions [46].
The learning algorithm maintains a history of state-action-reward triples (s, a, r) from previous rounds, stored in matrices S~t~, A~t~, and R~t~. This historical data trains the policy π~t~ for subsequent rounds, enabling the system to progressively identify more effective strain modifications through iterative experimentation [46].
Traditional Strain Optimization Protocol
Traditional strain optimization follows a conventional DBTL cycle that relies heavily on researcher expertise and manual intervention:
- Design Phase: Researchers identify potential genetic modifications based on literature review, known metabolic pathways, and prior experimental results. This typically involves selecting promoter sequences, ribosome binding sites, or gene deletions/overexpressions expected to enhance product yield [46].
- Build Phase: Laboratory implementation of designed strains using standard genetic engineering techniques such as PCR, restriction digestion, ligation, and transformation [46].
- Test Phase: Cultivation of engineered strains in appropriate media with monitoring of growth metrics, substrate consumption, and product formation through analytical methods like HPLC or GC-MS [46].
- Learn Phase: Manual data analysis by domain experts to interpret results, formulate hypotheses about limiting factors or regulatory constraints, and plan subsequent design iterations [46].
This traditional approach faces significant limitations due to its reliance on human intuition for navigating complex biological systems with incomplete mechanistic understanding, often requiring numerous iterative cycles to achieve substantial improvements [46].
AI Clinical Data Validation Protocol
Beyond direct strain optimization, AI systems demonstrate significant utility in clinical data validation, employing a hybrid approach that combines large language models (LLMs) with deterministic clinical algorithms [10]. The Octozi platform exemplifies this methodology:
- Data Processing: Unified data pipelines continuously ingest and contextualize diverse clinical trial data from multiple sources, including electronic data capture (EDC) systems [10].
- Discrepancy Detection: The system identifies clinically meaningful discrepancies across six categories: (1) inappropriate concomitant medication for adverse events; (2) misaligned timing of medication administration and adverse events; (3) incorrect severity scores based on event descriptions; (4) mismatched dosing changes; (5) incorrect causality assessment; and (6) missing supporting data for adverse events [10].
- Human-AI Collaboration: AI-generated insights are presented through interfaces that maintain human oversight while dramatically improving efficiency. This enables medical reviewers to focus on complex clinical judgment rather than routine data reconciliation [10].
This protocol has demonstrated a 6.03-fold increase in data cleaning throughput while simultaneously reducing errors from 54.67% to 8.48% in controlled studies with experienced medical reviewers [10].
Workflow Visualization
The fundamental differences between traditional and AI-augmented approaches become apparent when comparing their operational workflows. The following diagrams illustrate the distinct processes and decision points for each methodology.
Diagram 1: Traditional strain optimization faces limitations with manual, time-consuming cycles that often yield suboptimal results due to biological complexity [46].
Diagram 2: AI-driven strain optimization uses continuous learning to efficiently navigate the design space, achieving target yields faster [46].
Ethical Framework and Data Governance
The implementation of AI-driven methods introduces significant ethical considerations that must be addressed through robust governance frameworks. The following diagram illustrates the core ethical principles and their practical implementation requirements for responsible AI innovation in strain optimization and clinical research.
Diagram 3: Ethical AI framework balances innovation with fundamental rights protection through specific implementation practices [65].
Data Privacy and Security Implementation
Protecting sensitive research and clinical data in AI-driven strain optimization requires comprehensive privacy and security measures:
- Data Minimization: Collect and process only personal data strictly necessary for the intended purpose, minimizing retention of unnecessary information to reduce privacy risks [65].
- Anonymization and De-identification: Employ techniques to remove or obfuscate personally identifiable information while preserving data utility for AI systems [65].
- Robust Encryption: Implement advanced encryption methods for data protection both in transit and at rest, regularly updating protocols to address emerging cyber threats [65].
- Access Controls: Establish strict role-based access policies limiting data viewing and modification to authorized personnel based on job functions [65].
- Continuous Monitoring: Conduct regular audits and automated monitoring of data practices to identify vulnerabilities, unusual activity, or unauthorized access [65].
Regulatory Compliance and Transparency
AI systems used in clinical research and drug development must meet evolving regulatory standards and transparency requirements:
- FDA Framework: The FDA's 2025 draft guidance establishes a risk-based assessment framework categorizing AI applications as low, medium, or high-risk based on their potential impact on patient safety and trial outcomes [8].
- Explainability Requirements: AI systems must provide interpretable outputs that healthcare professionals can understand and validate, with technical approaches that identify key contributing features to AI predictions [8].
- Documentation Standards: Comprehensive validation requires documenting training dataset characteristics (size, diversity, representativeness, bias assessment), model architecture, algorithm selection rationale, and performance benchmarking [8].
- Global Compliance: Adherence to regulations including GDPR (EU), CCPA (California), HIPAA (healthcare data), and emerging AI-specific regulations such as the EU AI Act is essential for legal operation across jurisdictions [65] [66].
Essential Research Reagents and Materials
Successful implementation of strain optimization methodologies requires specific research tools and platforms. The table below details essential solutions for both traditional and AI-driven approaches.
Table 2: Research reagent solutions for strain optimization and data validation
| Research Solution | Function/Purpose | Application Context |
|---|---|---|
| Multi-Well Plates | Enables parallel cultivation of microbial strains for high-throughput screening | Traditional and AI-driven strain optimization [46] |
| E. coli k-ecoli457 Model | Genome-scale kinetic model serving as in silico surrogate for validating optimization methods | AI strain optimization validation [46] |
| HPLC/GC-MS Systems | Analytical measurement of metabolite concentrations and product yields | Strain performance assessment [46] |
| Octozi Platform | AI-assisted medical data cleaning combining LLMs with clinical algorithms | Clinical data validation [10] |
| Cloud AI Infrastructure | Scalable computing resources for training and deploying reinforcement learning models | AI-driven strain optimization [8] |
| Electronic Data Capture (EDC) | Centralized collection of clinical trial data from multiple sources | Clinical data management [10] |
| Galaxy Platform | Modular, FAIR-principles compliant environment for automated workflows | Synthetic biology pipeline implementation [30] |
| Edit Check Systems | Programmatic validation of clinical data using Boolean logic and historical thresholds | Traditional clinical data cleaning [10] |
The comparative analysis demonstrates that AI-driven approaches offer substantial advantages over traditional methods in strain optimization and clinical data validation, with documented improvements in efficiency, accuracy, and cost-effectiveness. Multi-Agent Reinforcement Learning enables model-free optimization of microbial strains without complete mechanistic understanding of cellular regulation [46], while AI-assisted clinical data cleaning achieves 6-fold throughput improvements with simultaneous error reduction [10].
However, these performance gains must be balanced against significant ethical imperatives concerning data privacy, informed consent, and algorithmic fairness. Responsible innovation requires implementing privacy-by-design principles, ensuring transparency in AI decision-making, and maintaining human oversight for critical judgments [65]. As regulatory frameworks evolve with the FDA's 2025 guidance on AI in clinical trials [8] and emerging AI-specific regulations globally [66], researchers and drug development professionals must prioritize ethical considerations alongside technical performance.
The future of strain optimization and clinical research lies in human-AI collaboration models that leverage the strengths of both approaches. AI systems excel at processing complex datasets and identifying non-intuitive patterns, while human researchers provide crucial domain expertise, ethical judgment, and clinical insight. By adopting this collaborative framework with robust ethical safeguards, the scientific community can accelerate drug development and bioprocess optimization while maintaining the trust of patients, regulators, and the public.
The integration of artificial intelligence into scientific research represents a fundamental shift from traditional, intuition-driven discovery to a new paradigm of augmented intelligence. In this new framework, AI does not replace human expertise but systematically enhances it, creating a synergistic partnership that leverages the unique strengths of both. For researchers, scientists, and drug development professionals, this partnership offers unprecedented opportunities to accelerate discovery while maintaining the creative insight and contextual understanding that define scientific excellence. The core premise is that human scientific intuition, when systematically augmented by AI's computational power and pattern recognition capabilities, can achieve what neither could accomplish alone [67] [68].
This transformation is particularly evident in pharmaceutical research and development, where AI is revolutionizing traditional models by seamlessly integrating data, computational power, and algorithms to enhance efficiency, accuracy, and success rates [69]. The transition is not merely technological but conceptual, moving from viewing AI as a tool to understanding it as an intelligent partner in the research process. This partnership enables researchers to extend their cognitive capabilities, with AI handling complex data synthesis and pattern recognition while human talent focuses on higher-order judgment, creativity, and strategic thinking [67]. As we explore the quantitative evidence, implementation frameworks, and practical applications of this partnership, it becomes clear that the future of scientific discovery lies in optimizing these human-AI collaborations.
Quantitative Performance: Human-AI Collaboration vs. Traditional Methods
Cross-Domain Performance Analysis
Rigorous evaluation of human-AI systems across multiple domains reveals a complex but promising picture of enhanced capabilities. A comprehensive 2024 meta-analysis published in Nature Human Behaviour examining 106 experimental studies provides crucial insights into when these collaborations succeed [70]. The analysis reveals that task type significantly influences the success of human-AI collaboration, with creation tasks showing positive synergy and decision tasks often demonstrating performance losses compared to the best performer alone [70].
Table 1: Cross-Domain Performance of Human-AI Collaboration
| Domain | Task Type | Performance Gain vs. Human Alone | Synergy (vs. Best Performer) | Key Factors |
|---|---|---|---|---|
| General Research | Decision Tasks | Moderate Improvement | -0.27 (Performance Loss) | AI overconfidence reduces human oversight |
| General Research | Creation Tasks | Significant Improvement | +0.19 (Performance Gain) | Complementary strengths in ideation |
| Clinical Trials | Patient Recruitment | 42.6% faster screening | 87.3% matching accuracy | NLP processing of medical records [8] |
| Clinical Trials | Document Automation | N/A | 50% cost reduction | Automated regulatory paperwork [8] |
| Engineering | Structural Design | 40% productivity gain | Weeks to seconds for iterations | AI-powered design systems [21] |
| Engineering | Structural Analysis | N/A | Faster computation with equal accuracy | Surrogate modeling [21] |
| Pharmaceutical | Drug Discovery | Reduced timelines & costs | Enhanced success rates | Target discovery & molecule design [69] |
The data reveals a crucial insight: the relative performance of humans and AI alone significantly determines the success of their collaboration. When humans outperform AI alone, combinations show an average synergy of +0.46, a medium-sized effect. Conversely, when AI outperforms humans alone, performance losses occur in the combined system with an effect size of -0.54 [70]. This suggests that effective partnerships require awareness of relative strengths rather than assuming AI superiority.
Pharmaceutical-Specific Applications
In pharmaceutical research, the quantitative benefits of human-AI collaboration are particularly striking. The global AI-based clinical trials market reached $9.17 billion in 2025, reflecting widespread adoption across pharmaceutical companies and research institutions [8]. These technologies demonstrate measurable improvements in efficiency and accuracy across the drug development pipeline.
Table 2: AI Augmentation in Pharmaceutical R&D
| Application Area | Traditional Performance | AI-Augmented Performance | Enhancement Mechanism |
|---|---|---|---|
| Legal Research (Document Review) | Baseline | 70% reduction in review time | AI-assisted analysis [67] |
| Medical Diagnostics | Human expert baseline | 15-20% higher accuracy in specific conditions | Multimodal data fusion [67] |
| Molecular Generation | Manual design & screening | Novel drug molecule creation & activity prediction | AI-facilitated creation [69] |
| Clinical Trial Design | Historical data analysis | Predictive outcome modeling & optimized parameters | Machine learning algorithms [69] [8] |
| Patient Recruitment | Manual screening | 42.6% faster screening with 87.3% accuracy | EHR analysis & predictive matching [8] |
| Quality Control | Manual inspection | Up to 25% waste reduction through early defect detection | AI-powered quality control systems [42] |
The implementation of AI in clinical research delivers substantial return on investment through enhanced efficiency, improved quality, and accelerated timelines. Medical coding systems save approximately 69 hours per 1,000 terms coded while achieving 96% accuracy compared to human experts [8]. Furthermore, AI automation eliminates time-intensive manual work across clinical trial operations, enabling resource optimization through intelligent allocation of personnel and materials based on predictive analytics [8].
Experimental Protocols: Validating Human-AI Collaboration
Framework for Hybrid Decision-Making
The Hybrid AI-Augmented Decision Optimization (HAI-HDM) framework provides a systematic approach for validating human-AI collaboration in scientific contexts [71]. This framework bridges artificial intelligence and human expertise to deliver context-aware, data-driven recommendations tailored to research environments. The protocol consists of five core components that can be adapted for various scientific domains:
Data Acquisition and Preprocessing: Collect diverse data sources including experimental results, historical research data, and contextual scientific knowledge. Implement rigorous data cleaning and normalization procedures to ensure quality inputs for AI systems.
AI-Powered Analysis and Ranking: Apply machine learning algorithms to analyze complex datasets and generate preliminary recommendations. For transparency, integrate explainable AI (XAI) tools including SHapley Additive exPlanations (SHAP) and Local Interpretable Model-agnostic Explanations (LIME) to make the foundation behind each recommendation interpretable [71].
Human-AI Decision Integration: Implement a dynamic weighting mechanism that adjusts the influence of human judgment and AI confidence based on the degree of uncertainty and specific research context. This ensures context-aware, human-in-the-loop decisions.
Explainable Recommendation Generation: Present outputs in formats that enable researchers to evaluate AI recommendations effectively, highlighting key contributing factors and confidence metrics.
Adaptive Learning: Employ reinforcement learning that leverages feedback from real-world experimental outcomes to continuously improve AI recommendations, creating a learning system that evolves with research progress [71].
This framework's effectiveness was validated through a case study focused on technology adoption, showing how it aligns analytical power with human insight to support informed decision-making while building trust in AI-driven strategic planning [71].
Regulatory Validation Protocols
For human-AI systems in regulated environments like pharmaceutical development, specific validation protocols are essential. The FDA's 2025 draft guidance "Considerations for the Use of Artificial Intelligence to Support Regulatory Decision-Making for Drug and Biological Products" establishes a comprehensive framework [8]. The validation approach includes:
Table 3: AI Validation Requirements for Regulated Research
| Validation Component | Protocol Requirements | Documentation Standards |
|---|---|---|
| Risk Assessment | Categorize AI models into three risk levels based on potential impact on patient safety and trial outcomes | Document risk classification rationale and mitigation strategies |
| System Validation | Comprehensive documentation extending beyond traditional software validation protocols | Training dataset characteristics including size, diversity, representativeness, and bias assessment results |
| Performance Benchmarking | Accuracy metrics, reliability testing, and generalizability studies | Model architecture documentation including algorithm selection rationale and parameter optimization procedures |
| Explainability | Implementation of technical approaches that identify key contributing features to AI predictions | Detailed descriptions of how AI models process input data and generate outputs |
| Continuous Monitoring | Regular performance validation and data drift detection | Change control documentation and performance monitoring records |
The European Union's regulatory framework under the AI Act and EudraLex Annex 22 provides additional specific guidelines for pharmaceutical applications, emphasizing that "Generative AI and Large Language Models (LLMs) are explicitly excluded from critical GMP applications" in favor of human-in-the-loop approaches [42]. These systems must log features in the test data that contributed to classification or decisions using feature attribution techniques like SHAP and LIME, and log the model's confidence score for each result, with low confidence scores flagged as "undecided" for human review [42].
The Augmented Research Workflow
The integration of human expertise and artificial intelligence follows a systematic workflow that enhances each stage of the scientific process. The diagram below illustrates this collaborative research cycle:
This workflow demonstrates the continuous interplay between human expertise and AI capabilities throughout the research process. Human researchers provide contextual understanding, creative hypothesis generation, and theoretical framing, while AI systems contribute pattern recognition across large datasets, predictive modeling for experimental design, and real-time data analysis. The integration points represent critical decision moments where both human and AI inputs inform the research direction [67] [68].
In practice, this collaborative cycle enables researchers to extend their cognitive capabilities significantly. For example, in drug discovery, AI can process millions of data points to identify potential molecular targets, while researchers apply domain knowledge to evaluate biological plausibility and therapeutic relevance [69]. This partnership transforms the research process from sequential steps to an integrated, iterative cycle where human intuition and machine intelligence continuously inform and enhance each other [68].
Decision Framework for Human-AI Collaboration
Successful implementation of human-AI partnerships requires careful consideration of when each approach excels. Research indicates that the effectiveness of collaboration depends significantly on task characteristics and the relative strengths of humans and AI systems [70]. The following decision framework guides researchers in optimizing these partnerships:
This decision framework is grounded in empirical research showing that "when humans outperformed AI alone, we found performance gains in the combination, but when AI outperformed humans alone, we found losses" [70]. The framework emphasizes:
Task-Specific Strategies: Creation tasks (open-ended, innovative work) show significantly better collaboration outcomes than decision tasks (structured, analytical work) [70]. This suggests that for hypothesis generation and experimental design, human-AI collaboration excels, while for binary decision points, clear ownership may be more effective.
Performance-Based Role Assignment: When humans outperform AI on a specific task, collaboration creates strong synergy (+0.46 effect size). Conversely, when AI outperforms humans, combined systems often show performance losses (-0.54 effect size) [70]. This indicates that the superior performer should typically lead with verification from the other.
Complementary Strength Alignment: The most effective partnerships systematically identify and leverage the unique strengths of both humans and AI. Human strengths include contextual understanding, creativity, and ethical judgment, while AI excels at data processing, pattern recognition, and computational scale [68].
Implementation of this framework requires honest assessment of relative capabilities and intentional design of collaboration protocols rather than assuming synergy will naturally emerge.
Essential Research Reagents: The Human-AI Toolkit
Successful implementation of human-AI partnerships in scientific research requires both technological and human elements. The following table details key components of the augmented research toolkit:
Table 4: Research Reagents for Human-AI Collaboration
| Tool/Component | Category | Function | Implementation Example |
|---|---|---|---|
| Explainable AI (XAI) Frameworks | Software | Provides interpretable AI outputs for researcher validation | SHAP/LIME for model interpretability [71] |
| Multimodal AI Systems | Software | Integrates and reasons across diverse data types (text, image, audio) | Holistic understanding of complex scientific scenarios [67] |
| Adaptive AI Architectures | Infrastructure | Enables flexible, modular integration of evolving AI capabilities | Cloud-native platforms with MLOps pipelines [67] |
| Digital Twin Technology | Analytical | Creates virtual simulations of biological systems or processes | Virtual patient models for clinical trial optimization [8] |
| Natural Language Processing (NLP) | Software | Processes unstructured text data from scientific literature | Analysis of medical records and research papers [8] |
| AI Literacy Training | Human Capital | Develops workforce competence in AI collaboration concepts | Comprehensive reskilling programs to address talent gap [67] |
| Hybrid Decision Protocols | Process Framework | Systematically integrates human judgment with AI recommendations | Dynamic weighting mechanisms based on uncertainty [71] |
| Validation and Governance Systems | Compliance | Ensures regulatory compliance and model reliability | Risk-based assessment frameworks per FDA guidelines [8] [42] |
These components work together to create an ecosystem where human intuition and AI capabilities can be effectively integrated. The technological elements provide the computational foundation, while the human and process elements ensure that researchers can maintain scientific rigor and oversight throughout the collaborative process.
The optimization of human-AI partnerships represents a transformative opportunity for scientific research, but requires deliberate strategy rather than opportunistic adoption. The evidence indicates that these collaborations yield the strongest results when they leverage complementary strengths rather than treating AI as a simple replacement for human effort [68] [70]. Success factors include:
Task-Aligned Collaboration: Creation-focused tasks like hypothesis generation and experimental design show stronger synergy than decision-focused tasks, suggesting the need for different collaboration models based on research phase [70].
Performance-Aware Role Assignment: Partnerships thrive when the relative strengths of humans and AI are honestly assessed, with leadership assigned to the superior performer for specific tasks [70].
Explainable and Transparent Systems: For researchers to trust and effectively collaborate with AI systems, they require interpretable outputs that align with scientific standards of evidence and verification [71] [42].
Continuous Learning and Adaptation: The most effective human-AI partnerships incorporate feedback mechanisms that allow both human researchers and AI systems to evolve their approaches based on outcomes [71].
For the pharmaceutical and research professionals navigating this transition, the strategic imperative is clear: organizations must pivot from fragmented AI initiatives to holistic, augmented intelligence strategies that systematically enhance human capabilities [67]. This requires investment not only in technology infrastructure but also in AI literacy development, workflow redesign, and governance frameworks that support ethical, effective collaboration [67] [42].
The future of scientific discovery lies not in choosing between human intuition and artificial intelligence, but in systematically optimizing their partnership. By implementing evidence-based frameworks for collaboration, maintaining scientific rigor through explainable AI systems, and strategically aligning strengths, researchers can achieve unprecedented advances in knowledge and therapeutic development. The organizations that master this integration will define the next era of scientific progress.
Proof in Performance: A Framework for Validating AI-Optimized Strains
The field of microbial strain optimization and drug discovery is undergoing a profound transformation, moving from traditional, labor-intensive methods toward artificial intelligence (AI)-driven approaches. This paradigm shift represents nothing less than a fundamental reimagining of biological research and development, compressing timelines that once required years into months or even weeks. Where traditional methods long relied on cumbersome trial-and-error and human-driven workflows, AI-powered discovery engines now offer the potential to compress timelines, expand chemical and biological search spaces, and redefine the speed and scale of modern pharmacology [9]. This comprehensive analysis objectively compares these competing approaches, providing researchers with quantitative performance data, detailed experimental protocols, and implementation frameworks for benchmarking AI-driven strain optimization against established traditional methods.
The urgency of this comparison stems from remarkable clinical progress. By 2025, AI-designed therapeutics have advanced into human trials across diverse therapeutic areas, with positive Phase IIa results reported for compounds like Insilico Medicine's Traf2- and Nck-interacting kinase inhibitor for idiopathic pulmonary fibrosis [9]. This rapid clinical translation demands rigorous benchmarking to establish scientific credibility and validate AI's claimed advantages. This guide provides the methodological framework for that essential validation.
Quantitative Performance Benchmarking
The transition to AI-driven methodologies is justified by substantial improvements in key performance metrics. The tables below provide a comparative analysis of efficiency, clinical output, and validation requirements.
Table 1: Comparative Efficiency Metrics for Strain Optimization and Early Drug Discovery
| Performance Metric | Traditional Methods | AI-Driven Approaches | Comparative Improvement |
|---|---|---|---|
| Discovery to Preclinical Timeline | ~5 years (industry standard) | As little as 18-24 months [9] | ~60-70% faster |
| Design Cycle Time | Industry standard baseline | ~70% faster [9] | ~70% reduction |
| Compounds Synthesized | Industry standard baseline | 10x fewer required [9] | 90% reduction |
| Strain Optimization Convergence | Manual, iterative tuning | Model-free RL guided by previous experiments [46] | Faster convergence to optimum |
| Data Processing Speed | Traditional baseline | Up to 5x faster processing [72] | 400% improvement |
Table 2: Clinical Pipeline Output and Validation Rigor (2025 Landscape)
| Characteristic | Traditional Methods | AI-Driven Platforms | Implications |
|---|---|---|---|
| Clinical-Stage Candidates | Established pipeline | >75 AI-derived molecules in clinical stages by end of 2024 [9] | Maturing clinical validation |
| Representative Compound | Conventional small molecules | ISM001-055 (Insilico Medicine) Phase IIa, Zasocitinib (Schrödinger) Phase III [9] | Clinical proof-of-concept emerging |
| Regulatory Acceptance | Established pathways | Evolving FDA/EMA guidance on AI in development [9] | Increasing regulatory familiarity |
| Validation Mindset | Independent replication by each lab | Collaborative validation models sharing data and protocols [3] | Reduced redundancy, higher quality |
| Success Rate Question | Known historical rates | "Is AI delivering better success, or just faster failures?" [9] | Still requires longitudinal study |
Table 3: Validation Requirements Across Methodologies
| Validation Component | Traditional Validation | AI Model Validation | Collaborative Validation Model |
|---|---|---|---|
| Primary Objective | Confirm method reliability for intended use [3] | Assess predictive accuracy on unseen data | Share development work and establish standardization [3] |
| Data Requirements | Internal experimental data | Large, high-quality training datasets | Published validation data from originating FSSP [3] |
| Implementation Burden | Each lab performs full validation | Significant computational resources needed | Verification only if following published method exactly [3] |
| Cross-Comparability | Limited between labs | Model-dependent | Direct cross-comparison of data between labs using same method [3] |
| Transparency | Often proprietary | "Black box" challenge with some models | Peer-reviewed publication of validation data [3] |
Experimental Protocols and Workflows
AI-Driven Multi-Agent Reinforcement Learning Protocol for Strain Optimization
The following protocol details the implementation of Multi-Agent Reinforcement Learning (MARL) for metabolic engineering, which has demonstrated capability to improve production of compounds like L-tryptophan in yeast beyond mechanistic knowledge [46].
Objective: To optimize metabolic enzyme levels using a model-free MARL approach that learns from experimental data to maximize product yield without requiring prior knowledge of the metabolic network or its regulation.
Key Components:
- Actions (a ∈ A = Râ¿áµƒ): Real-valued vectors specifying changes to enzyme expression levels.
- States (s ∈ S = Râ¿Ë¢): Vectors representing steady-state concentrations of metabolites and enzymes.
- Rewards (râ‚œ ∈ R): The change in target variable (e.g., product yield) between consecutive rounds: râ‚œ = yâ‚œ - yₜ₋â‚.
- Policy (π: S ↦ A): Mapping from states to actions, learned from historical data.
Experimental Workflow:
- Initialization: Define controllable enzyme targets and establish baseline cultivation conditions.
- Parallel Cultivation: In each round (t), run multiple cultivations simultaneously (e.g., using multi-well plates or parallel bioreactors).
- State Observation: Measure metabolite concentrations and enzyme levels during pseudo-steady-state (e.g., exponential growth phase).
- Reward Calculation: Quantify target variable improvement (yâ‚œ - yₜ₋â‚) from previous round.
- Policy Update: Update policy πₜ using Maximum Margin Regression (MMR) on history ℋₜ = {Sₜ, Aₜ, Rₜ} of state-action-reward triples.
- Action Selection: Apply updated policy πₜ to determine enzyme level modifications for next round.
- Iteration: Repeat steps 2-6 until yield optimization converges or reaches target threshold.
Validation: Algorithm performance should be evaluated on speed of convergence, noise tolerance, and statistical stability of solutions using genome-scale kinetic models as surrogate for in vivo behavior [46].
Traditional Design-Build-Test-Learn (DBTL) Protocol
The traditional DBTL cycle represents the established methodology for strain optimization, relying heavily on domain expertise and sequential experimentation.
Objective: To improve microbial strain performance through iterative cycles of design, construction, testing, and analysis.
Experimental Workflow:
- Design Phase: Researchers manually evaluate strain performance data and propose genetic modifications based on domain expertise and literature review. Designs often focus on pathway enzyme overexpression, knockout of competing pathways, or regulatory element engineering.
- Build Phase: Implement genetic designs using molecular biology techniques (PCR, cloning, CRISPR-Cas9, etc.). This includes promoter engineering, ribosomal binding site modification, and codon optimization. Transform constructs into host strain and verify genetically.
- Test Phase: Cultivate engineered strains in appropriate media (minimal or complex) under defined conditions (shake flask or bioreactor). Measure key performance indicators: product yield, productivity, titer, biomass formation, and substrate consumption.
- Learn Phase: Analyze experimental results to identify metabolic bottlenecks or regulatory issues. This manual evaluation informs the next design phase, continuing the iterative optimization process.
Validation: Methods must be fit-for-purpose following accreditation standards, with all parameters documented for reliability and admissibility [3].
Signaling Pathways and Metabolic Engineering Logic
AI-driven strain optimization requires understanding the complex interplay between metabolic pathways and regulatory networks. The following diagram illustrates key metabolic engineering targets and optimization relationships.
The Scientist's Toolkit: Essential Research Reagents and Solutions
Successful implementation of both traditional and AI-driven strain optimization requires specific laboratory resources and computational tools.
Table 4: Essential Research Reagents and Platforms for Strain Optimization
| Reagent/Platform | Type | Primary Function | Application Context |
|---|---|---|---|
| k-ecoli457 Model | Computational | Genome-scale kinetic model serving as in silico surrogate for E. coli behavior [46] | Algorithm validation and training |
| Multi-well Plates | Laboratory Consumable | Enable parallel cultivation for high-throughput screening [46] | Both traditional and AI-driven approaches |
| MARL Algorithm | Computational Tool | Model-free reinforcement learning for optimizing enzyme levels [46] | AI-driven strain optimization |
| Synthetic DNA/ Oligonucleotides | Molecular Biology | Implement genetic designs for pathway engineering | Both traditional and AI-driven approaches |
| Elicit/ ResearchRabbit | AI Literature Tool | Automate literature reviews and paper screening [73] | Research acceleration and hypothesis generation |
| NVivo/ Atlas.ti | Qualitative Analysis | AI-powered qualitative data analysis for coding and synthesis [73] | Mixed-methods research integration |
| Open Source MARL Implementation | Computational Resource | Publicly available algorithm code for strain optimization [46] | Method replication and customization |
The comprehensive benchmarking data presented reveals a field at an inflection point. AI-driven approaches demonstrate unambiguous advantages in speed and efficiency, compressing discovery timelines by 60-70% and reducing experimental burden by requiring significantly fewer synthesized compounds [9]. The emergence of over 75 AI-derived molecules in clinical trials by the end of 2024 provides tangible evidence that these methodologies are delivering concrete outputs, not just theoretical promises [9].
However, the establishment of a true gold standard requires more than demonstrable efficiency gains. It demands rigorous validation frameworks, transparent methodologies, and collaborative verification models [3]. The most successful research teams will be those that strategically integrate both approaches—using AI to accelerate discovery and exploration while applying traditional scientific rigor for validation and verification. As the field matures, the gold standard is evolving from any single methodology to a integrated approach that leverages the strengths of both paradigms: the unprecedented speed and scale of AI with the proven reliability and regulatory acceptance of traditional methods.
For researchers embarking on this transition, the protocols, benchmarks, and toolkits provided here offer a practical foundation for rigorous comparison and implementation. The future of strain optimization and drug discovery lies not in choosing between these paradigms, but in intelligently integrating them to achieve previously impossible scientific breakthroughs.
This guide provides an objective, data-driven comparison between AI-driven strain optimization and traditional empirical methods in biopharmaceutical research and development. The analysis is framed within the broader thesis that AI-driven validation represents a paradigm shift, offering significant advantages in speed, efficiency, and predictive power for microbial strain and bioprocess development.
The integration of Artificial Intelligence (AI) and Machine Learning (ML) into bioprocess and strain optimization is fundamentally reshaping R&D timelines and outcomes. The table below summarizes the key performance metrics, demonstrating the quantitative advantages of AI-driven methods over traditional approaches.
Table 1: Key Performance Indicators (KPIs) for Strain Optimization Methods
| Metric | AI-Driven Methods | Traditional Empirical Methods | Supporting Data & Context |
|---|---|---|---|
| Speed / Timelines | 70-90% faster discovery and optimization cycles [15] [9]. Can reduce multi-year processes to months [74]. | Typically requires 3-5 years for discovery and pre-clinical work [15]. | AI-designed drug candidates have reached Phase I trials in under 2 years, a fraction of the traditional ~5-year timeline [9]. |
| Yield / Productivity | 75.7% improvement in final product titer demonstrated in AI-optimized bioprocesses [75]. Achieves 2 to 4-fold yield increases in optimized systems [74]. | Incremental improvements; highly dependent on researcher intuition and trial-and-error. | In cell-free system optimization, AI-driven screening achieved a 1.9 to 2.1-fold increase in protein yield and cost-effectiveness [74]. |
| Cost Efficiency | Up to 40% reduction in discovery and development costs [15]. Can lead to fourfold reduction in unit cost of expressed proteins [74]. | High material and labor costs due to extensive manual experimentation. | The global AI in pharma market is forecast to grow at a CAGR of 27% (2025-2034), reflecting its value and cost-saving potential [15]. |
| Success Rates | Aims to increase the probability of clinical success, which is traditionally only ~10% [15]. | Low success rates; ~10% of drug candidates progress from clinical trials to approval [15]. | By analyzing vast datasets to identify promising candidates earlier, AI methods are poised to improve the likelihood of technical and clinical success [15]. |
Detailed Experimental Protocols and Methodologies
The performance gains highlighted above are realized through specific, reproducible AI-driven workflows. The following sections detail the core experimental protocols that generate these results, providing a blueprint for their implementation.
Protocol for AI-Driven Dynamic Bioprocess Optimization
This methodology, used to achieve a 75.7% increase in antibiotic titer, integrates real-time data acquisition with AI-based control for unprecedented precision in fermentation processes [75].
- Objective: To dynamically control microbial metabolism to maximize the yield of a target compound, such as gentamicin C1a, during fed-batch fermentation.
- Key Modules:
- Kinetic Modeling: A Backpropagation Neural Network (BPNN) is trained to capture non-linear correlations between process variables (e.g., substrate consumption rates, growth rates) and production rates. High model accuracy is critical (R² > 0.95) [75].
- Multi-Objective Optimization: A genetic algorithm (NSGA-II) is used to resolve trade-offs between competing metabolic demands (e.g., growth vs. production) and identify optimal feeding strategies [75].
- Real-Time Sensing: Dual near-infrared (NIR) and Raman spectroscopy are employed for continuous, non-invasive monitoring of key biochemical parameters in the bioreactor [75].
- Closed-Loop Feedback Control: The system uses the AI model's predictions and sensor data to automatically adjust nutrient feeds (carbon, nitrogen, oxygen) in real-time without human intervention [75].
- Outcome Validation: The optimized process is validated by comparing the final titer, yield, and specific productivity against benchmarks from traditional fixed-protocol fermentation.
AI-Driven Fermentation Control Loop
Protocol for High-Throughput AI-Guided Strain & System Screening
This approach uses microfluidics and machine learning to efficiently navigate a vast combinatorial space of conditions or genetic constructs, drastically reducing the time and cost of optimization [74].
- Objective: To rapidly identify the optimal combination of components (e.g., nutrients, additives, genetic parts) for a high-yielding cell-free gene expression (CFE) system or cellular strain.
- Key Steps:
- Droplet-Based Microfluidics: A microfluidic device generates picoliter-sized droplets, each acting as an independent bioreactor. The device creates massive combinatorial libraries by merging a "carrier" droplet (with cell extract and DNA) with "satellite" droplets containing different sets of components [74].
- Fluorescent Color-Coding (FluoreCode): Each satellite droplet is labeled with a unique fluorescent color and intensity, encoding its specific composition. This allows for high-throughput tracking of thousands of unique combinations in parallel [74].
- In-Droplet Screening: Droplets are incubated, and the yield of a fluorescent reporter protein (e.g., sfGFP) is measured to assess the performance of each combination [74].
- In Silico Optimization with ML: The experimental data (FluoreCode vs. yield) is used to train a machine learning model. This model predicts high-yield combinations beyond the tested experimental space, which are then validated in the lab [74].
- Outcome Validation: The final simplified and optimized formula is tested by expressing multiple target proteins to confirm increased yield and reduced unit cost compared to the baseline formulation [74].
AI-Guided High-Throughput Screening Workflow
The Scientist's Toolkit: Essential Research Reagents & Solutions
Successful implementation of AI-driven optimization relies on a suite of specialized reagents, software, and hardware. This table details the key components for the featured experimental protocols.
Table 2: Essential Research Reagent Solutions for AI-Driven Optimization
| Category | Item / Solution | Function & Application |
|---|---|---|
| Computational & AI Tools | Neural Network Potentials (NNPs) [76] | Pre-trained models (e.g., OMol25 NNPs) for predicting molecular energies and properties, accelerating in-silico design. |
| Multi-Objective Optimization Algorithms (e.g., NSGA-II) [75] | AI algorithms that resolve trade-offs between competing objectives (e.g., growth vs. production) to find optimal process parameters. | |
| Large Language Models (LLMs) [77] | Assists in translating natural language problem descriptions into mathematical models for optimization. | |
| Specialized Reagents & Kits | Cell-Free Gene Expression (CFE) System [74] | A versatile platform using crude cellular extracts for rapid protein expression without maintaining living cells; the target for optimization. |
| Fluorescent Dyes & Reporter Proteins (sfGFP) [74] | Used for color-coding droplet libraries and as a high-throughput readout for system productivity (yield). | |
| PEG-PFPE Surfactant [74] | A biocompatible surfactant crucial for stabilizing emulsion droplets during microfluidic screening. | |
| Hardware & Analytics | Microfluidic Droplet Generator [74] | Core hardware for generating picoliter-sized reactors, enabling massive parallel experimentation. |
| Dual NIR & Raman Spectrometers [75] | Enables real-time, non-invasive monitoring of bioreactor conditions, providing data for AI-driven feedback control. | |
| Benchmarking & Validation | Experimental Reduction-Potential & Electron-Affinity Datasets [76] | Curated experimental data used to benchmark and validate the accuracy of computational methods (AI vs. DFT). |
| Electronic Health Records (EHRs) & Real-World Data (RWD) [15] [78] | Data sources used for training AI models for clinical trial design and monitoring post-market performance of AI-enabled products. |
The Critical Role of Human-Relevant Models and Automated Biology Platforms
The traditional drug discovery model is showing signs of strain. The observation that drug development is becoming slower and more expensive over time, known as Eroom's Law, has become an uncomfortable truth for the industry [79]. A critical factor in this inefficiency is the heavy reliance on animal models that frequently fail to predict human responses. Analyses of clinical trial data reveal that up to 90% of drugs that appear safe and effective in animal studies ultimately fail once they reach human trials [80]. This translational gap leads to staggering consequences: billions of dollars wasted, delays in new therapies, and patients left without meaningful options.
The limitations of animal models are becoming harder to ignore. Key reasons for this translational failure include:
- Species Differences: Variations in metabolism, immune response, and disease pathways between animals and humans.
- Limited Disease Representation: Inability of animal models to fully recapitulate the complexity and heterogeneity of human diseases.
- Insufficient Predictive Power: Poor translation of safety and efficacy signals from preclinical models to human clinical trials.
In response, a transformative shift is underway toward human-relevant models and automated biology platforms. These approaches aim to align drug development more closely with human biology, offering a path to more predictive, efficient, and successful therapeutic development.
Performance Comparison: Human-Relevant Models vs. Traditional Methods
The quantitative advantages of adopting human-relevant models and automated platforms are evident across multiple performance metrics. The tables below summarize key comparative data.
Table 1: Predictive Performance and Translational Value
| Metric | Traditional Animal Models | Human-Relevant & Automated Platforms |
|---|---|---|
| Clinical Failure Rate | ~90% of drugs fail in human trials despite animal success [80] | Emerging technology; potential to significantly reduce failure |
| Safety Failure Cause | ~30% of failures due to unmanageable toxicity not predicted in animals [80] | Human organs-on-chips can reveal human-specific toxicities |
| Efficacy Failure Cause | ~50% of failures due to lack of efficacy in humans [80] | Models using human tissues reflect human disease biology |
| Data Resolution | Lower; limited sampling, endpoint analyses | Higher; continuous, multi-omic data from integrated sensors |
| Translational Concordance | Low for specific targets (e.g., liver toxicity) | High for human-specific metabolic and toxicological pathways |
Table 2: Operational Efficiency and Throughput
| Metric | Traditional Methods | Automated & Integrated Platforms |
|---|---|---|
| Experiment Scalability | Low; resource-intensive, limited by animal housing | High; platform-based, parallel processing (e.g., 6-well to 96-well formats) [12] |
| Process Integration | Low; often disjointed steps requiring manual intervention | High; unified "design-build-test-learn" cycles (e.g., BioAutomata) [81] |
| Data Structuring for AI | Poor; fragmented data, inconsistent metadata | High; native data traceability and robust metadata capture [12] |
| Timeline for Protein Production | Weeks for challenging proteins (e.g., membrane proteins) | Under 48 hours from DNA to purified protein [12] |
| Reproducibility | Variable due to biological and technical noise | High; standardized automated protocols reduce human variation [12] |
Experimental Protocols for Key Platforms
Protocol: Ex Vivo Perfused Human Organ Testing for Drug Safety
This methodology uses donated human organs maintained on perfusion systems to evaluate drug candidates, providing a unique, human-specific safety profile.
- 1. Organ Sourcing and Consent: Human organs that cannot be used for transplantation are redirected for research with full informed consent from the donor or their family. Organs are transported using clinical-grade preservation systems.
- 2. Perfusion System Setup: The organ is connected to a perfusion machine that circulates a warm, oxygenated, blood-like fluid, maintaining it in a physiologically active state for hours or days.
- 3. Drug Administration and Dosing: A drug candidate is introduced into the perfusion circuit at a predefined concentration. Dosing can be single or repeated, mimicking clinical regimens.
- 4. Real-Time Monitoring and Sampling: Responses are monitored in real-time through:
- Functional Imaging: Assessing organ structure and dynamic function.
- Fluid Biomarker Analysis: Frequent sampling of the perfusate for enzymes (e.g., liver transaminases), metabolites, and inflammatory markers.
- Tissue Biopsies: Sequential biopsies for detailed histopathology and molecular analysis (e.g., transcriptomics).
- 5. Data Integration and Analysis: High-resolution data is integrated to build a comprehensive picture of the drug's effect, capturing subtle metabolic and toxicological pathways that animal models may miss.
Protocol: Automated High-Throughput GPCRome Screening
This platform uses automated systems to screen traditional medicine compounds against the entire library of human G protein-coupled receptors (GPCRs) to identify novel ligands [82] [83].
- 1. Platform Design: A uniform approach is used to establish a comprehensive panel of cell lines, each expressing a unique human GPCR coupled to a standardized reporter system.
- 2. Compound Library Preparation: Extracts and purified compounds from traditional medicines (e.g., alkaloids, flavonoids, terpenoids) are prepared in source plates using liquid handling robots.
- 3. Automated Assaying:
- Cells are dispensed into assay plates.
- Compounds are transferred to the cell plates via non-contact dispensing.
- The system incubates plates under controlled conditions.
- 4. Signal Detection and Activation Profiling: A plate reader measures the reporter signal (e.g., fluorescence, luminescence) after a set period. The activation profile for each compound across the entire GPCRome is generated.
- 5. Hit Confirmation and Characterization: Primary hits are retested in dose-response experiments. Advanced techniques like competitive ligand-binding assays (CLBA) or label-free fluorescent methods are used to confirm direct binding and characterize the pharmacological mode of action (agonist, antagonist) [82].
Diagram 1: Integrated drug safety testing workflow, comparing human-relevant and traditional paths.
The Scientist's Toolkit: Essential Research Reagent Solutions
Table 3: Key Reagents and Platforms for Human-Relevant, Automated Biology
| Item | Function & Application |
|---|---|
| Automated Liquid Handlers (e.g., Tecan Veya, Eppendorf Research 3 neo) | Precise, high-throughput dispensing of reagents and compounds for assay setup, enabling reproducibility and walk-up automation [12]. |
| GPCR-Expressing Cell Line Libraries | Pre-engineered cell panels representing the human GPCRome for systematic ligand screening and target deconvolution of complex mixtures like traditional medicines [82] [83]. |
| Phenotypic Reporter Assays | Engineered signaling pathway readouts (e.g., cAMP, Ca²âº, β-arrestin) to determine the functional activity and signaling bias of compounds on GPCRs and other targets. |
| Defined Human Cell Lines (iPSCs, Primary Cells) | Biologically relevant human cells providing a more accurate model of human disease and toxicology compared to immortalized or animal-derived cell lines. |
| Specialized Growth Matrices (for 3D Cultures) | Hydrogels and scaffolds that support the development of complex 3D tissue structures like organoids, enhancing physiological relevance. |
| Label-Free Detection Reagents | Non-radioactive, fluorescent, or luminescent reagents for binding (e.g., fluorescent CLBA) and functional assays, facilitating safer and more efficient high-throughput screening [82]. |
Signaling Pathways and Workflow in Automated Strain Optimization
The convergence of AI and synthetic biology is revolutionizing biological discovery and engineering [81]. In the context of AI-driven strain optimization for producing therapeutic compounds, this involves a tightly integrated, automated cycle.
Diagram 2: AI-driven automated strain optimization cycle.
- DESIGN: AI models, including Biological Design Tools (BDTs) and Large Language Models (LLMs), analyze vast datasets to predict genetic constructs that optimize the microbial strain for producing a target compound [81]. This involves in silico modeling of metabolic pathways, promoter strength, and enzyme variants.
- BUILD: Automated platforms, such as Nuclera's eProtein Discovery System, execute the physical construction of the designed genetic parts. This includes gene synthesis, assembly, and transformation into the host organism, moving from DNA to functional strain in a highly parallelized manner [12].
- TEST: Engineered strains are cultured in automated systems (e.g., MO:BOT for 3D cultures) [12]. The output is measured using high-throughput analytics to quantify compound yield, growth, and other key performance indicators, generating rich, structured data.
- LEARN: AI/ML algorithms process the test results to identify patterns and correlations. This learning informs the next cycle of design, creating a closed-loop system that continuously improves strain performance with minimal human intervention [81].
The evidence demonstrates that human-relevant models and automated biology platforms critically address the high failure rates and inefficiencies of traditional drug discovery. By providing human-specific biological data early in the development process and leveraging AI to accelerate optimization, these approaches are building a more predictive and efficient path from bench to bedside. The integration of ex vivo human organ testing, automated screening platforms, and AI-driven strain optimization represents a fundamental shift toward a system where biology drives discovery, and technology enables its execution at scale. As these tools continue to mature and gain regulatory acceptance, they promise to deliver safer and more effective therapies to patients faster.
Navigating the Regulatory Landscape for AI-Generated Therapeutics
The integration of artificial intelligence (AI) into therapeutic development represents a paradigm shift, compressing traditional drug discovery timelines from years to months. By 2025, AI spending in the pharmaceutical industry is projected to reach $3 billion, reflecting its critical role in reshaping development pipelines [15]. AI-driven platforms have demonstrated the potential to reduce drug discovery costs by up to 40% and slash development timelines from five years to as little as 12-18 months [15]. This transformative acceleration challenges existing regulatory frameworks, necessitating new approaches for evaluating AI-generated therapeutics that balance innovation with patient safety. The regulatory landscape is evolving rapidly, with agencies like the FDA and EMA issuing new guidance to address the unique challenges posed by AI, including algorithmic transparency, data quality, and adaptive learning systems [84] [85].
Comparative Analysis of Global Regulatory Frameworks
Side-by-Side Comparison of Major Regulatory Approaches
Table 1: Comparative overview of global regulatory frameworks for AI in drug development
| Regulatory Agency | Key Guidance/Document | Core Approach | Risk Framework | Unique Features |
|---|---|---|---|---|
| US FDA | "Considerations for the Use of AI to Support Regulatory Decision-Making for Drug and Biological Products" (2025 Draft Guidance) [85] | Risk-based credibility assessment for specific Context of Use (CoU) [85] | Seven-step credibility assessment framework [85] | Focus on AI used in regulatory decision-making; excludes early discovery unless impacting safety [84] |
| European Medicines Agency (EMA) | "AI in Medicinal Product Lifecycle Reflection Paper" (2024) [85] | Rigorous upfront validation and comprehensive documentation [85] | Risk-based approach for development, deployment, and monitoring [85] | Issued first qualification opinion on AI methodology in March 2025 [85] |
| UK MHRA | "Software as a Medical Device" (SaMD) and "AI as a Medical Device" (AIaMD) [85] | Principles-based regulation [85] | "AI Airlock" regulatory sandbox for testing [85] | Focus on human-centered design and interpretability [85] |
| Japan PMDA | Post-Approval Change Management Protocol (PACMP) for AI-SaMD (2023) [85] | "Incubation function" to accelerate access [85] | Predefined, risk-mitigated modifications post-approval [85] | Allows continuous algorithm improvement without full resubmission [85] |
Regulatory Challenges and Fragmentation
The current regulatory landscape for AI in drug development is characterized by significant fragmentation, creating barriers to coherent oversight [84]. This fragmentation manifests in three key areas: inconsistent definitions of AI across jurisdictions, differing oversight approaches for AI-enabled medical devices versus AI-generated therapeutics, and varying guidelines from international regulatory bodies [84]. For AI-generated therapeutics, oversight primarily focuses on the safety and efficacy of the final drug product, with AI treated as a component of the development process rather than a directly regulated entity [84]. This contrasts with AI-enabled medical devices, where the algorithms themselves undergo direct evaluation [84].
The FDA's Context of Use (CoU) framework presents both opportunities and challenges for AI regulation. The CoU defines the specific circumstances under which an AI application is intended to be used, outlining its purpose, scope, target population, and decision-making role [84]. However, the application of this framework to novel AI methodologies remains unclear, potentially creating regulatory uncertainty for sponsors developing unprecedented AI-enabled therapies [84].
Performance Comparison: AI-Driven Platforms vs. Traditional Methods
Clinical Pipeline and Success Metrics of Leading AI Platforms
Table 2: Performance metrics of leading AI-driven drug discovery platforms
| Company/Platform | Key AI Technology | Clinical-Stage Candidates | Discovery Timeline | Reported Efficiency Gains |
|---|---|---|---|---|
| Exscientia | Generative AI ("Centaur Chemist"), automated design-make-test-learn cycle [9] | 8 clinical compounds designed (as of 2023), including CDK7 & LSD1 inhibitors [9] | Design cycles ~70% faster with 10x fewer synthesized compounds [9] | Substantially faster than industry standards; closed-loop automation [9] |
| Insilico Medicine | Generative deep learning for target discovery and molecular design [9] | ISM001-055 for idiopathic pulmonary fibrosis (Phase IIa) [9] | Target to Phase I in 18 months [9] | Accelerated discovery and preclinical work [9] |
| Schrödinger | Physics-enabled ML design [9] | TYK2 inhibitor zasocitinib (Phase III) [9] | Reached late-stage clinical testing [9] | Physics-based approach for molecular simulation [9] |
| BenevolentAI | Knowledge-graph-driven target discovery [9] | Multiple candidates in pipeline [9] | AI-powered target selection [9] | Partnership with AstraZeneca for chronic kidney disease [15] |
| Traditional Methods | Empirical screening, manual optimization | Varies by company | ~5 years for discovery and preclinical [9] | Baseline for comparison; high failure rates [15] |
Quantitative Impact on Drug Development Efficiency
AI-driven approaches demonstrate significant advantages across multiple development metrics. By 2025, an estimated 30% of new drugs will be discovered using AI, representing a substantial shift in industry practices [15]. The economic impact is equally impressive, with AI projected to generate $350-$410 billion annually for the pharmaceutical sector through innovations in development, clinical trials, and precision medicine [15]. Clinical development alone could see up to $25 billion in savings through AI optimization [15].
Success rates represent another crucial differentiator. Traditional drug development sees only about 10% of candidates progressing through clinical trials, while AI-driven methods show potential to increase this probability by identifying more promising candidates earlier in the process [15]. Companies like Recursion and Exscientia have merged to create integrated platforms combining phenomic screening with automated precision chemistry, further accelerating the transition from discovery to clinical validation [9].
Experimental Protocols and Methodologies
FDA's Credibility Assessment Framework for AI Models
The FDA's risk-based credibility assessment framework provides a structured approach for evaluating AI models in drug development [85]. This seven-step methodology establishes evidence-based trust in AI model performance for specific contexts of use:
- Define Context of Use (CoU): Precisely specify the AI model's purpose, scope, and role in regulatory decision-making [85].
- Identify Model Requirements: Determine necessary model capabilities, performance thresholds, and operational constraints [85].
- Select Model Design: Choose appropriate algorithms, architectures, and training methodologies [85].
- Verify Implementation: Ensure correct technical implementation and computational reproducibility [85].
- Perform Analytical Validation: Assess model performance against predefined metrics using independent test datasets [85].
- Assess Clinical Validity: Evaluate model ability to accurately predict clinically relevant endpoints [85].
- Establish Lifecycle Management: Implement protocols for monitoring, updating, and maintaining model performance over time [85].
AI-Driven Strain Optimization and Validation Workflow
Advanced AI platforms employ integrated workflows that connect computational design with experimental validation:
Target Identification: AI algorithms analyze genomic, proteomic, and clinical datasets to identify novel therapeutic targets [15]. Knowledge graphs integrate heterogeneous biological data to prioritize targets with strong disease association [9].
Generative Molecular Design: Deep learning models generate novel molecular structures optimized for target binding, selectivity, and drug-like properties [9]. Reinforcement learning incorporates multi-parameter optimization during the design process [15].
In Silico Profiling: Physics-based simulations and machine learning models predict pharmacokinetics, toxicity, and off-target effects [9]. Digital twins and organ-on-chip technologies enhanced by AI provide sophisticated safety simulations [36].
Experimental Validation: Automated synthesis and high-throughput screening validate AI-designed candidates [9]. Phenotypic screening on patient-derived cells provides translational relevance assessment [9].
Iterative Optimization: Closed-loop systems use experimental results to refine AI models, enabling continuous improvement of candidate compounds [9].
The Scientist's Toolkit: Essential Research Reagents and Platforms
Table 3: Key research reagents and technology platforms for AI-driven therapeutic development
| Tool Category | Specific Technologies/Platforms | Function in AI-Driven Development |
|---|---|---|
| AI/ML Software Platforms | Exscientia's Centaur Chemist, Insilico Medicine's Generative Tensorial Reinforcement Learning (GENTRL), Schrödinger's Physics-Based Platforms [9] | Generative molecular design, binding affinity prediction, de novo compound generation |
| Data Analytics & Integration | Knowledge Graphs (BenevolentAI), Phenomic Screening Databases (Recursion) [9] | Integrate heterogeneous biological data, identify novel target-disease associations |
| Automation & Robotics | Laboratory Automation Systems (AutomationStudio), High-Throughput Screening Robotics [9] | Enable rapid synthesis and testing of AI-designed compounds, closing design-make-test-learn loop |
| Advanced Screening Models | Organ-on-Chip (OoC) platforms, Patient-Derived Organoids, Digital Twins [36] | Provide human-relevant physiological models for validation, reduce animal testing |
| Multi-Omics Technologies | Genomics, Transcriptomics, Proteomics, Metabolomics platforms [37] | Generate comprehensive datasets for AI model training and validation |
| Cloud Computing Infrastructure | Amazon Web Services (AWS), Google Cloud Platform, Specialized AI Processors [9] | Provide computational power for training complex AI models and managing large datasets |
Regulatory Pathways for AI-Generated Therapeutics
Navigating the Approval Process for AI-Derived Candidates
The regulatory pathway for AI-generated therapeutics involves navigating both traditional approval processes and AI-specific considerations. Key aspects include:
Preclinical Development: AI-enhanced digital twins and organ-on-chip technologies provide human-relevant safety and efficacy data, supporting the 3Rs principle (Replace, Reduce, Refine) in animal testing [36]. These technologies enable more predictive toxicology assessments while addressing ethical concerns [36].
Investigational New Drug (IND) Application: Sponsors must provide comprehensive documentation of AI methodologies used in candidate selection and optimization [85]. This includes detailed description of training data, model validation, and performance metrics specific to the Context of Use [85]. The FDA's credibility assessment framework guides evidence requirements for AI-derived components of the application [85].
Clinical Trial Optimization: AI tools for patient stratification, recruitment, and protocol design must demonstrate reliability and absence of bias [85]. Regulatory expectations include transparency in algorithm functionality and validation against relevant patient populations [85].
Post-Marketing Surveillance: Adaptive AI systems for pharmacovigilance require predefined change control plans and ongoing performance monitoring [85]. The FDA's predetermined change control plan framework, initially developed for AI-enabled medical devices, offers a model for managing algorithm updates post-approval [84].
International Harmonization Efforts
The lack of global regulatory alignment for AI in drug development creates significant challenges for multinational development programs [84]. While the US, EU, UK, and Japan have all issued guidance, these frameworks differ in scope, terminology, and application [84]. The AI-enabled Ecosystem for Therapeutics (AI2ET) framework has been proposed as a conceptual model to support regulatory knowledge federation and promote international alignment [84]. Key policy recommendations include strengthening international cooperation through organizations like the International Council for Harmonisation, establishing shared regulatory definitions, and investing in regulatory capacity building across jurisdictions [84].
The regulatory landscape for AI-generated therapeutics is evolving rapidly to keep pace with technological advancements. While significant progress has been made through FDA draft guidance, EMA reflection papers, and innovative approaches from other international regulators, challenges remain in achieving global harmonization and addressing the unique characteristics of adaptive AI systems [84] [85]. The successful integration of AI into therapeutic development will require ongoing collaboration between industry, regulators, and researchers to establish robust, flexible frameworks that ensure patient safety without stifling innovation. As AI continues to transform drug development, regulatory science must similarly advance to provide clear pathways for evaluating these groundbreaking technologies, ultimately accelerating patient access to novel therapies.
The adoption of Artificial Intelligence (AI) in biopharmaceutical development represents a paradigm shift from traditional, often empirical, methods towards data-driven, predictive bioengineering. This transition is particularly impactful in the domain of strain optimization, a critical process for producing therapeutic proteins, vaccines, and other biologics. AI-driven methodologies are demonstrating a profound ability to accelerate development timelines and enhance yields, moving beyond the limitations of conventional trial-and-error approaches. This guide objectively compares the performance of AI-optimized strains and traditional methods, providing a detailed analysis of supporting experimental data and protocols for research professionals.
Performance Comparison: AI-Optimized vs. Traditional Strain Engineering
The quantitative superiority of AI-driven approaches is evident across key performance metrics, including development speed, yield improvement, and resource efficiency. The table below summarizes comparative data from real-world case studies.
Table 1: Performance Comparison of AI-Optimized vs. Traditional Strain Engineering
| Metric | AI-Optimized Workflows | Traditional Workflows | Supporting Case Study |
|---|---|---|---|
| Project Timeline | ~12 months from sequence to scalable process [86] | Typically several years [15] | Ginkgo Bioworks [86] |
| Yield Improvement | 10-fold increase in protein yield [86] | Incremental, single-fold improvements common | Ginkgo Bioworks [86] |
| Strain Screening Efficiency | A single DBTL cycle screened ~300 strains, achieving a 5-fold yield increase [86] | Labor-intensive, low-throughput screening | Ginkgo Bioworks [86] |
| Strain Construction Efficiency | AI-designed molecules reached clinical trials in ~2 years [9]; 70% faster design cycles with 10x fewer synthesized compounds [9] | ~5 years for discovery and preclinical work [9] | Exscientia [9] |
| Cell-Free Protein Synthesis (CFPS) Optimization | 2- to 9-fold yield increase in 4 experimental cycles [87] | Requires extensive, time-consuming combinatorial testing [87] | Automated DBTL Pipeline [87] |
Detailed Experimental Protocols & Methodologies
Case Study 1: AI-DrivenE. coliExpression System for Vaccine Enzyme
Background: A partner company faced critical supply constraints for a key enzyme required for scaling up their vaccine production. Initial in-house production attempts failed to meet scale-up requirements [86].
Objective: Develop a commercially viable E. coli expression system for the enzyme within a stringent timeline.
Experimental Protocol:
This study employed a dual-workflow strategy, running Strain Engineering and Fermentation Process Development concurrently [86].
1. Strain Engineering Workflow:
- Design Phase: A targeted library of approximately 300 DNA constructs was designed. The library varied key genetic parts while maintaining the enzyme's amino acid sequence, including:
- DNA recoding (codon optimization)
- Promoter variants
- Plasmid backbones
- Ribozyme variants
- Ribosome Binding Sites (RBSs) [86]
- Build Phase: An in-house DNA synthesis team constructed and cloned the plasmids into an E. coli expression host within weeks [86].
- Test Phase: High-throughput assays for enzyme titer and activity were developed. The entire library was screened, and the top 22 producing strains (~7% hit rate) were selected for further analysis, already showing a 5-fold yield improvement [86].
- Design Phase: A targeted library of approximately 300 DNA constructs was designed. The library varied key genetic parts while maintaining the enzyme's amino acid sequence, including:
2. Fermentation Process Development Workflow:
- Parameter Identification & Optimization: Critical fermentation parameters were identified. A statistical Design of Experiment (DoE) approach was used to optimize the process based on these parameters [86].
- Scale-Up & Industrialization: The best-performing strain from the engineering workflow was scaled up. The media was tailored to meet vaccine manufacturing regulatory requirements, and genetic stability was monitored throughout the fermentation run [86].
Outcome: The synergistic integration of both workflows delivered a 10-fold increase in protein yield within a year. The partner was able to transfer the process and produce more enzyme in a single run than in the entire previous year [86].
Case Study 2: Automated DBTL for Cell-Free Protein Synthesis Optimization
Background: Optimizing a Cell-Free Protein Synthesis (CFPS) system is complex and time-consuming due to the vast combinatorial space of its components [87].
Objective: Create a fully automated, modular DBTL pipeline to optimize CFPS yields for antimicrobial proteins (colicins M and E1) in E. coli and HeLa-based systems [87].
Experimental Protocol:
- Design Phase:
- AI-Powered Code Generation: All Python scripts for experimental design were generated using ChatGPT-4 from natural language prompts, without manual code revision, dramatically reducing development time [87].
- Active Learning Strategy: An improved Batch Active Learning (AL) strategy, the Cluster Margin (CM) method, was employed. This algorithm selects experiments that are both highly informative for the model and diverse from each other, maximizing learning efficiency per experimental cycle [87].
- Build & Test Phases:
- Learn Phase:
- The resulting data was used to retrain the model, which then proposed the next batch of experiments in an iterative loop [87].
Outcome: The platform achieved a 2- to 9-fold increase in colicin yield in just four DBTL cycles, demonstrating the power of integrated automation and AI for rapid biological optimization [87].
Workflow Visualization
The following diagrams illustrate the core logical workflows underpinning the successful AI-driven strain optimization case studies.
AI-Driven Strain & Process Development Workflow
Automated Design-Build-Test-Learn (DBTL) Cycle
The Scientist's Toolkit: Key Research Reagent Solutions
The successful implementation of AI-driven strain optimization relies on a foundation of specific reagents, software, and hardware. This table details essential components from the featured case studies.
Table 2: Essential Research Reagents and Platforms for AI-Driven Strain Optimization
| Category | Item/Platform | Function in Experimental Protocol |
|---|---|---|
| Genetic Parts | DNA Construct Library (Promoters, RBS, Codon Variants) | Provides genetic diversity for screening optimal expression elements [86]. |
| Host Organism | E. coli Expression Strains | Industry-standard workhorse for recombinant protein production [86]. |
| Cell-Free System | CFPS Kit (E. coli or HeLa extract) | Minimalist, transcription-translation system for rapid protein prototyping and production [87]. |
| AI/Software | Active Learning Algorithms (e.g., Cluster Margin) | Intelligently selects the most informative experiments to minimize costly trials [87]. |
| AI/Software | Large Language Models (e.g., ChatGPT-4) | Automates code generation for experimental design and workflow control, democratizing automation [87]. |
| Automation Hardware | Automated Liquid Handlers | Executes high-throughput pipetting for building genetic constructs and setting up assays [86] [87]. |
| Analytics Hardware | Plate Readers / HTP Assays | Provides rapid, quantitative measurement of key outputs like protein titer and activity [86]. |
| Data Management | Galaxy Platform / FAIR-compliant systems | Ensures workflow reproducibility, data integrity, and interoperability [87]. |
The presented case studies provide compelling, data-driven validation that AI-optimized strains significantly outperform those developed through traditional methods. The key differentiators are unprecedented speed (reducing development from years to months), substantial yield enhancements (2- to 10-fold improvements), and superior resource efficiency through targeted experimentation. The fusion of AI-driven design with automated execution, as exemplified by the DBTL cycle, marks a new era in biopharmaceutical development. For researchers and drug development professionals, mastering these integrated platforms and methodologies is no longer a forward-looking advantage but an immediate imperative to maintain competitiveness and innovation capacity in the modern biopharma landscape.
Conclusion
The integration of AI into strain optimization is not merely an incremental improvement but a fundamental transformation of the discovery process. The evidence confirms that AI-driven methods offer unparalleled advantages in speed, cost-efficiency, and the ability to explore a vastly larger biological design space. However, the future lies not in the replacement of traditional methods but in their strategic fusion with AI. Success hinges on building robust, transparent, and ethically sound AI systems that generate trustworthy, validated results. As regulatory frameworks like the FDA's AI2ET model evolve, the industry must prioritize data quality, model interpretability, and human oversight. The ultimate goal is a synergistic ecosystem where AI handles data-intensive prediction and pattern recognition, freeing scientists to focus on critical thinking, experimental design, and translational insight, thereby accelerating the delivery of novel biologics to patients.
References
- 1. Artificial Intelligence-Driven Innovations in Oncology Drug ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12232943/]
- 2. AI-driven epitope prediction: a systematic review ... [https://www.nature.com/articles/s41541-025-01258-y]
- 3. Collaborative versus traditional method validation approach [https://pmc.ncbi.nlm.nih.gov/articles/PMC7452674/]
- 4. A Helping Hand: A Survey About AI-Driven Experimental ... [https://www.mdpi.com/2076-3417/15/9/5208]
- 5. Challenges in Analytical Method Development and ... [https://www.biopharminternational.com/view/challenges-analytical-method-development-and-validation]
- 6. Top Mistakes in Analytical Method Validation and How to ... [https://www.pharmoutsourcing.com/Featured-Articles/350046-Top-Mistakes-in-Analytical-Method-Validation-and-How-to-Avoid-Them/]
- 7. AI Route Optimization: Enhancing Delivery Efficiency in 2025 [https://www.descartes.com/resources/knowledge-center/ai-route-optimization-enhancing-delivery-efficiency]
- 8. AI Clinical Trials: Complete Guide for 2025 [https://nwai.co/ai-clinical-trials-complete-guide-for-2025/]
- 9. Leading AI-Driven Drug Discovery Platforms [https://www.sciencedirect.com/science/article/abs/pii/S0031699725075118]
- 10. A Comparative Study of AI-Assisted vs. Traditional Methods [https://arxiv.org/html/2508.05519]
- 11. MIT scientists debut a generative AI model that could ... [https://news.mit.edu/2025/mit-scientists-debut-generative-ai-model-that-could-create-molecules-addressing-hard-to-treat-diseases-1125]
- 12. Inside ELRIG's Drug Discovery 2025 [https://www.drugtargetreview.com/article/190237/inside-elrigs-drug-discovery-2025/]
- 13. How can we enhance biological research with AI? [https://sangerinstitute.blog/2024/12/18/how-can-we-enhance-biological-research-with-ai/]
- 14. Enabling AI in chemistry and biologics discovery [https://www.ddw-online.com/enabling-ai-in-chemistry-and-biologics-discovery-37278-202509/]
- 15. AI in Pharma and Biotech: Market Trends 2025 and Beyond [https://www.coherentsolutions.com/insights/artificial-intelligence-in-pharmaceuticals-and-biotechnology-current-trends-and-innovations]
- 16. AI-powered high-throughput digital colony picker platform ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12514280/]
- 17. The Future of Biopharmaceutical Research: Trends to ... [https://www.genemod.net/blog/the-future-of-biopharmaceutical-research-trends-to-watch-in-2025]
- 18. Harbour BioMed Launches First Fully Human Generative ... [https://www.harbourbiomed.com/news/250.html]
- 19. Deep active optimization for complex systems [https://www.nature.com/articles/s43588-025-00858-x]
- 20. Validation technique could help scientists make more ... [https://news.mit.edu/2025/validation-technique-could-help-scientists-make-more-accurate-forecasts-0207]
- 21. AI in Engineering: Boosting Efficiency & Innovation [https://monograph.com/blog/ai-engineering-efficiency-innovation-2025]
- 22. How to optimize the systematic review process using AI tools [https://pmc.ncbi.nlm.nih.gov/articles/PMC11143948/]
- 23. Artificial intelligence methods and approaches to improve ... [https://www.sciencedirect.com/science/article/pii/S266731852500011X]
- 24. Development and validation of a novel isocratic RP-HPLC ... [https://www.sciencedirect.com/science/article/pii/S092809872500274X]
- 25. AI-Ready Competency Framework for Biomedical Scientific ... [https://www.sciencedirect.com/science/article/pii/S1001929425000343]
- 26. A generalized platform for artificial intelligence-powered ... [https://www.nature.com/articles/s41467-025-61209-y]
- 27. EC Candidates -2025 [https://www.biocuration.org/ec-candidates-2025/]
- 28. Synergizing artificial intelligence and probiotics [https://www.sciencedirect.com/science/article/abs/pii/S0924224425000743]
- 29. Teaching AI to see: How the next era of digital pathology is ... [https://www.selectscience.net/article/teaching-ai-to-see-how-the-next-era-of-digital-pathology-is-being-driven-by-curated-biospecimen-data]
- 30. An AI-driven workflow for the accelerated optimization of ... [https://www.sciencedirect.com/science/article/pii/S2589004225018607]
- 31. Artificial Intelligence in Cancer Drug Discovery in 2025 [https://oncodaily.com/oncolibrary/artificial-intelligence-in-cancer-drug-discovery]
- 32. The Future of AI in Drug Development: 10 Trends That Will ... [https://huspi.com/blog-open/the-future-of-ai-in-drug-development-10-trends-that-will-redefine-rd/]
- 33. AI-Driven Drug Discovery: Accelerating Target ... [https://www.hyperec.com/blog/ai-driven-drug-discovery-accelerating-target-identification-and-validation/]
- 34. Transformative Role of Artificial Intelligence in Drug Discovery ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12406033/]
- 35. The best AI drug target prediction tools of 2025 [https://www.dip-ai.com/use-cases/en/the-best-AI-drug-target-prediction]
- 36. Artificial intelligence in preclinical research: enhancing ... [https://www.sciencedirect.com/science/article/pii/S135964462500073X]
- 37. Application and research progress on artificial intelligence in ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12575287/]
- 38. [2402.08703] A Survey of Generative for de novo Drug AI ... Design [https://arxiv.org/abs/2402.08703]
- 39. Using generative , researchers AI compounds that can kill... design [https://news.mit.edu/2025/using-generative-ai-researchers-design-compounds-kill-drug-resistant-bacteria-0814]
- 40. Generative AI in Drug Discovery Market 2025 Soars ... [https://www.towardshealthcare.com/insights/generative-ai-in-drug-discovery-market-sizing]
- 41. Guided multi-objective generative to enhance structure-based drug... AI [https://pubs.rsc.org/en/content/articlelanding/2025/sc/d5sc01778e]
- 42. AI in Pharma: Software & Validation in New EU Regulations [https://ttms.com/artificial-intelligence-in-pharma-software-implementation-and-validation-according-to-new-eu-regulations/]
- 43. Benchmarking the Structure-Based Virtual Screening ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12363558/]
- 44. A precise comparison of molecular target prediction methods [https://pubs.rsc.org/en/content/articlehtml/2025/dd/d5dd00199d]
- 45. AI-powered high-throughput digital colony picker platform ... [https://www.nature.com/articles/s41467-025-63929-7]
- 46. Strain design optimization using reinforcement learning - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC9200333/]
- 47. Differential Bio and CanBiocin Publish Case Study on AI‑ ... [https://www.differential.bio/news/case-study-canbiocin]
- 48. AI-powered drug development: 2025 Revolution [https://lifebit.ai/blog/ai-powered-drug-development-2025-revolution/]
- 49. Data Quality Management for AI Success: Your 2025 Guide [https://www.alation.com/blog/data-quality-management-ai-success-2025/]
- 50. AI vs Traditional Methods: A Comparative Analysis of Data ... [https://superagi.com/ai-vs-traditional-methods-a-comparative-analysis-of-data-driven-decision-making-in-2025/]
- 51. Top Data Quality Trends For 2025 [https://qualytics.ai/blog/data-quality-trends/]
- 52. 7 Essential Data Quality Best Practices for 2025 [https://www.getelyxai.com/en/blog/data-quality-best-practices]
- 53. How to Improve Data Quality: A Strategic Guide for 2025 [https://www.ewsolutions.com/how-to-improve-data-quality/]
- 54. What is AI bias? Causes, effects, and mitigation strategies [https://www.sap.com/resources/what-is-ai-bias]
- 55. Addressing AI bias: a human-centric approach to fairness [https://www.ey.com/en_us/insights/emerging-technologies/addressing-ai-bias-a-human-centric-approach-to-fairness]
- 56. Fair human-centric image dataset for ethical AI benchmarking [https://www.nature.com/articles/s41586-025-09716-2]
- 57. AI bias: exploring discriminatory algorithmic decision-making ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8830968/]
- 58. Bias in AI [https://www.chapman.edu/ai/bias-in-ai.aspx]
- 59. 11 Essential Benchmarks to Evaluate AI Model Performance ... [https://www.chatbench.org/what-are-the-key-benchmarks-for-evaluating-ai-model-performance/]
- 60. AI in Drug Development: Clinical Validation and ... [https://globalforum.diaglobal.org/issue/june-2025/ai-in-drug-development-clinical-validation-and-regulatory-innovation-are-dual-imperatives/]
- 61. AI Model Optimization Techniques for Enhanced ... [https://www.netguru.com/blog/ai-model-optimization]
- 62. Research [https://straindataproject.org/research]
- 63. 2025 Trends in Genetics & Breeding [https://www.rxgreentechnologies.com/blog/2025-trends-in-genetics-breeding/]
- 64. AI Efficiency Breakthroughs in Enterprise Optimization 2025 [https://sparkco.ai/blog/ai-efficiency-breakthroughs-in-enterprise-optimization-2025]
- 65. Data Privacy & AI Ethics Best Practices - TrustCommunity [https://community.trustcloud.ai/docs/grc-launchpad/grc-101/governance/data-privacy-and-ai-ethical-considerations-and-best-practices/]
- 66. Ethical AI: Protecting Data Privacy And User Consent In ... [https://www.adexchanger.com/data-driven-thinking/ethical-ai-protecting-data-privacy-and-user-consent-in-the-age-of-innovation/]
- 67. Oct 2025 AI Tools Redefine Human-AI Collaboration [https://thinkia.com/thoughts/enterprise-ai-revolution-oct-2025-ai-tools-redefine-human-ai-collaboration/]
- 68. The Human-AI Partnership — Building the Future Together [https://medium.com/@techyhello/the-human-ai-partnership-building-the-future-together-c65b39d34a6d]
- 69. The future of pharmaceuticals: Artificial intelligence in drug ... [https://www.sciencedirect.com/science/article/pii/S2095177925000656]
- 70. When combinations of humans and AI are useful [https://www.nature.com/articles/s41562-024-02024-1]
- 71. Balancing intelligence and intuition: a human-AI decision ... [https://peerj.com/articles/cs-3341/]
- 72. AI vs Traditional Methods: A Comparative Analysis of ... [https://superagi.com/ai-vs-traditional-methods-a-comparative-analysis-of-revenue-analytics-in-different-industries/]
- 73. Academic Research Methods Are Changing in 2025 [https://www.tremendous.com/blog/academic-research-method-trends/]
- 74. AI-driven high-throughput droplet screening of cell-free gene ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11923291/]
- 75. Artificial intelligence-driven dynamic regulation for high ... [https://pubs.rsc.org/en/content/articlehtml/2025/gc/d5gc02507a]
- 76. Benchmarking OMol25-Trained Models on Experimental ... [https://rowansci.com/publications/omol25-redox]
- 77. Artificial intelligence for optimization: Unleashing the ... [https://www.sciencedirect.com/science/article/abs/pii/S0377221725006666]
- 78. Evaluating AI-enabled Medical Device Performance in ... [https://www.fda.gov/medical-devices/digital-health-center-excellence/request-public-comment-measuring-and-evaluating-artificial-intelligence-enabled-medical-device]
- 79. From risk to resilience - Drug Discovery World (DDW) [https://www.ddw-online.com/from-risk-to-resilience-37536-202510/]
- 80. Beyond animal testing: How human data trials are ... [https://pharmaphorum.com/rd/beyond-animal-testing-how-human-data-trials-are-reshaping-drug-development]
- 81. The convergence of AI and synthetic biology: the looming ... [https://www.nature.com/articles/s44385-025-00021-1]
- 82. Emerging paradigms for target discovery of traditional medicines [https://pmc.ncbi.nlm.nih.gov/articles/PMC11910885/]
- 83. Emerging paradigms for target discovery of traditional ... [https://www.sciencedirect.com/science/article/pii/S2666675824002121]
- 84. Reimagining drug regulation in the age of AI: a framework for ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12571717/]
- 85. Regulating the Use of AI in Drug Development: Legal ... [https://www.fdli.org/2025/07/regulating-the-use-of-ai-in-drug-development-legal-challenges-and-compliance-strategies/]
- 86. Strain Engineering and Process Development to Deliver ... [https://biopharma.ginkgo.bio/resources/case-studies/strain-engineering-and-process-development-to-deliver-enzyme-expression-systems]
- 87. An AI-driven workflow for the accelerated optimization of ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12529354/]